2026-03-27

AI 早报 2026-03-27
概览
要闻
- 谷歌发布 Gemini 3.1 Flash Live,支持 90 种语言对话 ↗
#1
模型发布
- Suno 正式推出 Suno v5.5 模型及个性化声音等新功能 ↗
#2 - Cohere 发布开源语音识别模型 Cohere Transcribe ↗
#3 - Mistral AI 发布 Voxtral TTS 模型 ↗
#4 - OpenDataLab 发布 MinerU-Diffusion-V1 ↗
#5 - Meta 发布 TRIBE v2,三模态模型预测人脑 fMRI 响应 ↗
#6 - Chroma 发布 200 亿参数 Context-1,开源 agentic 搜索模型 ↗
#7 - 英伟达发布 gpt-oss-puzzle-88B 剪枝量化模型 ↗
#8
开发生态
- 智谱向所有 GLM Coding Plan 用户开放 GLM-5-Turbo 模型
#9 - Codex 上线 Plugins 插件功能 ↗
#10 - Claude Code 推出云端 auto-fix 功能,支持 PR 自动化修复 ↗
#11 - Anthropic 调整 Claude 高峰限制 ↗
#12 - Cline 推出 Cline Kanban,开源多 Agent 编排工具
#13
产品应用
- Gemini 新增功能支持导入其他 AI 应用记忆及聊天记录 ↗
#14 - Google Search Live 功能扩展至全球,覆盖超 200 个国家和地区 ↗
#15 - Google 翻译耳机实时翻译登陆 iOS,适用范围扩至七国 ↗
#16
技术与洞察
行业动态
前瞻与传闻
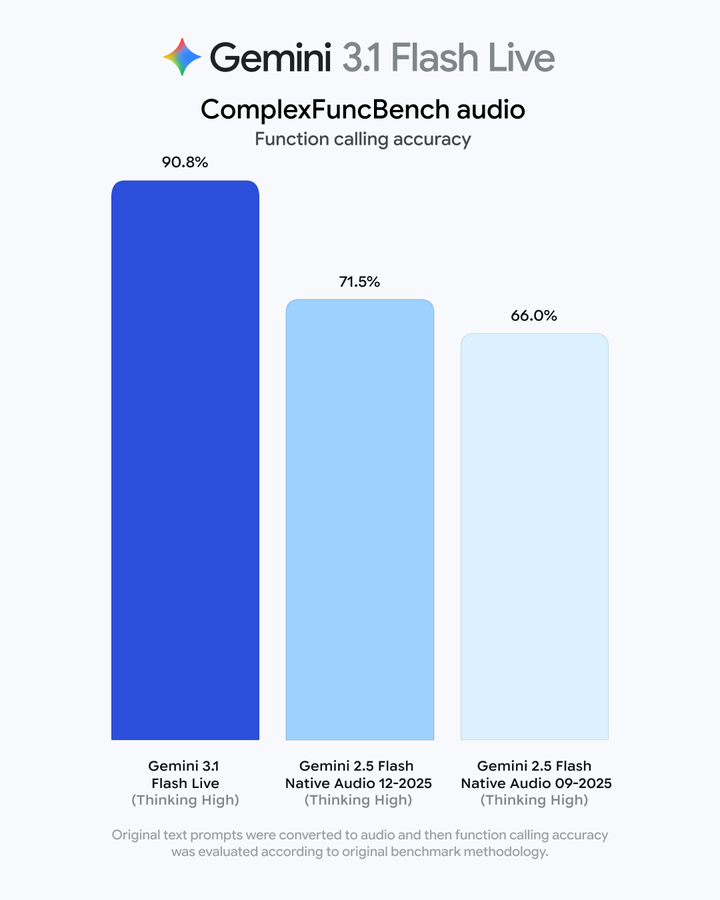
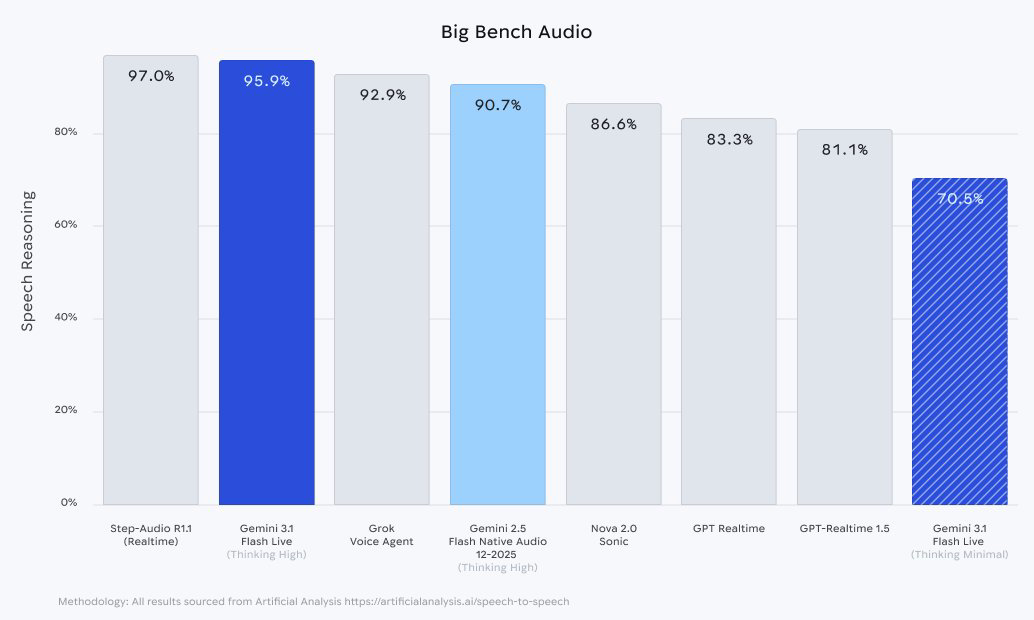
谷歌发布 Gemini 3.1 Flash Live,支持 90 种语言对话 #1
Google 正式发布 Gemini 3.1 Flash Live,该模型支持超过 90 种语言,在响应速度、抗噪能力及复杂指令遵循方面均有显著提升,并将对话上下文时长扩展至前代两倍。
开发者现可通过 Google AI Studio 的
Gemini Live API进行集成,普通用户可通过移动端 Gemini Live 及 Search Live 体验。
Google 正式发布 Gemini 3.1 Flash Live,官方将其称为迄今为止最高质量的音频和语音模型,旨在为开发者构建实时语音和视觉 Agent、企业客户服务以及消费者日常对话提供下一代语音优先 AI 体验。
该模型在延迟、可靠性和自然对话方面实现了显著提升,具备更快的响应速度、在嘈杂环境中更高的任务完成度、更强的复杂指令遵循能力、比 2.5 Flash Native Audio 更优的声学细节识别,并能将对话上下文时长提升至前代两倍。
在可用性方面,该模型现通过 Google AI Studio 中的 Gemini Live API 以预览版形式向开发者开放;通过 Gemini Enterprise for Customer Experience 面向企业开放;并通过 Gemini Live(覆盖 Android 和 iOS)以及 Search Live 面向普通用户开放,其中多语言能力推动了 Search Live 在超过 200 个国家和地区的扩张。
此外,该模型支持超过 90 种语言,且生成的所有音频均采用 SynthID 进行水印处理。

相关链接:
- https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-live/
- https://blog.google/innovation-and-ai/technology/developers-tools/build-with-gemini-3-1-flash-live/
- https://ai.google.dev/gemini-api/docs/live
Suno 正式推出 Suno v5.5 模型及个性化声音等新功能 #2
Suno 推出了 Suno v5.5 及三项个性化功能。
Pro 和 Premier 订阅用户可通过
Voices功能克隆自己声音唱歌,或用Custom Models微调出最多三个专属模型。所有用户则能通过
My Taste功能让系统学习自身的流派与情绪偏好。
Suno 正式推出 v5.5 模型,官方称其为目前最好且最具表现力的版本。同步上线 Voices、Custom Models 和 My Taste 三项功能。
Voices 和 Custom Models 面向 Pro 及 Premier 用户,前者允许捕获本人声音创作,内置隐私验证且仅限私有使用,未来计划增加共享;后者允许每人创建最多 3 个基于原创曲目的个性化模型。
My Taste 面向所有用户,通过学习偏好实现个性化。

相关链接:
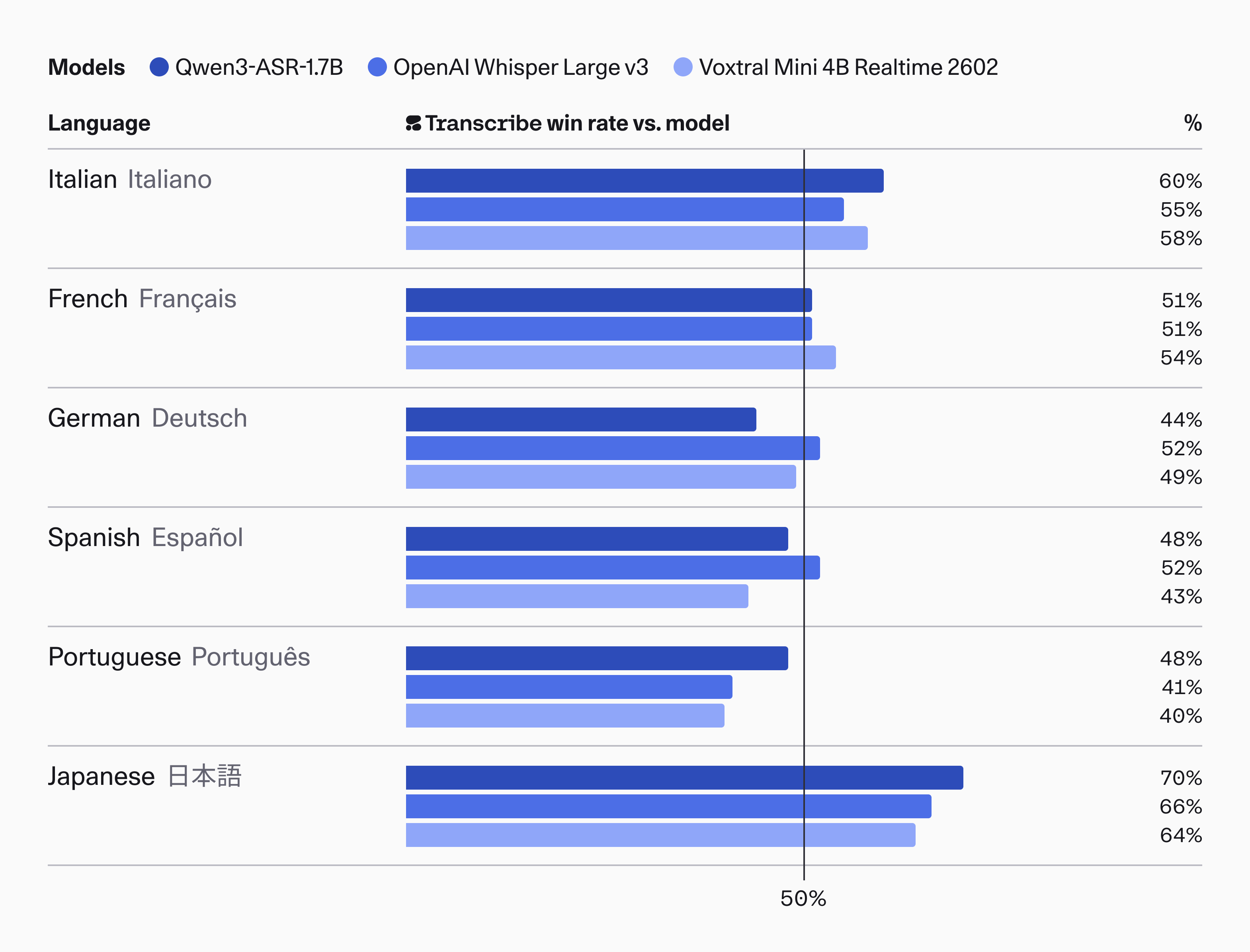
Cohere 发布开源语音识别模型 Cohere Transcribe #3
Cohere 推出了其首款开源语音识别模型 Cohere Transcribe,该模型拥有 20 亿 参数并采用
Apache 2.0协议。这款模型支持包含中文在内的 14 种语言,能通过 Cohere API 免费体验。
Cohere 发布了一款名为 Cohere Transcribe 的开源自动语音识别(ASR)模型。该模型拥有 20 亿 参数,采用 Apache 2.0 许可证,专为音频输入到文本输出的高效转录任务设计,支持英语、中文(普通话)等 14 种语言。
官方称该模型在英文识别上位列 Hugging Face Open ASR Leaderboard 榜首,且离线吞吐量最高可达同等规模专用 ASR 模型的三倍。
该模型现已上架 Hugging Face,可通过 Cohere API 免费体验。
相关链接:
- https://huggingface.co/CohereLabs/cohere-transcribe-03-2026
- https://huggingface.co/blog/CohereLabs/cohere-transcribe-03-2026-release
Mistral AI 发布 Voxtral TTS 模型 #4
Mistral AI 发布并开源了文本转语音模型
Voxtral TTS,该模型拥有 40 亿 参数,支持零样本语音克隆、跨语言语音迁移及 9 种语言,但不支持中文。
Mistral AI 近日发布其首个文本转语音模型 Voxtral TTS。该模型拥有 4B 参数,基于 Ministral 3B 构建,采用 transformer 自回归流匹配架构。
官方称其支持 9 种语言(不包含中文),仅需 3 秒参考音频实现零样本适配。
根据官方人类评估,该模型在自然度等维度优于 ElevenLabs Flash v2.5。
开源权重已在 Hugging Face 发布。

相关链接:
OpenDataLab 发布 MinerU-Diffusion-V1 #5
OpenDataLab 团队发布了 OCR 模型
MinerU-Diffusion-V1,该模型通过引入块级并行扩散解码替代传统的自回归解码,将文档 OCR 转化为逆向渲染问题,从而显著降低了长文档处理的序列延迟。
OpenDataLab 团队近日发布了 MinerU-Diffusion-V1,这是一款基于扩散模型的文档 OCR 框架。其核心在于将文档 OCR 重新定义为逆向渲染问题,并以 block-level parallel diffusion decoding 替代了传统的 autoregressive decoding。
根据官方提供的数据,该模型与 MinerU2.5 相比,最高可实现 3.26 倍的 TPS,并在 99.9% 相对精度下实现 2.12 倍加速,在 98.8% 相对精度下实现 3.01 倍加速。
相关链接:
- https://huggingface.co/opendatalab/MinerU-Diffusion-V1-0320-2.5B
- https://github.com/opendatalab/MinerU-Diffusion
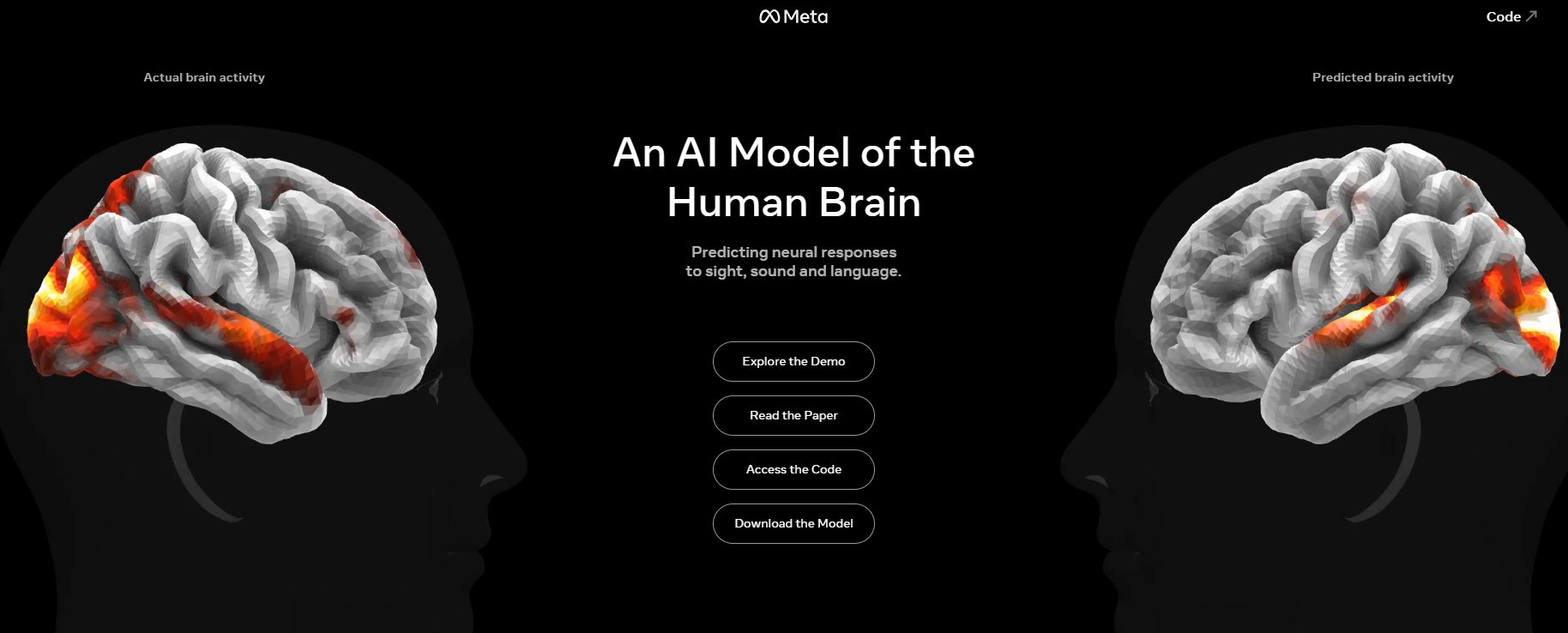
Meta 发布 TRIBE v2,三模态模型预测人脑 fMRI 响应 #6
Meta发布了面向计算机模拟神经科学的三模态基础模型 TRIBE v2。该模型基于超千小时、七百多名受试者的数据训练,通过整合
LLaMA 3.2等组件,能直接根据视频、音频和文本精准预测人类大脑的高分辨率fMRI响应。
Meta 近日公开 TRIBE v2,这是一款面向 in-silico neuroscience 的三模态基础模型。其架构整合 LLaMA 3.2、V-JEPA2 与 Wav2Vec-BERT,旨在基于视频、音频与文本预测人类 fMRI 脑响应。
官方论文称,该模型基于超 1000 小时、720 名受试者数据训练,相比传统线性编码模型精度提升数倍,支持 in silico experimentation 并复现经典实验结果。
当前相关论文、代码及权重已公开,旨在解决认知神经科学模型割裂问题,统一预测不同场景下的人脑活动。
相关链接:
- https://github.com/facebookresearch/tribev2
- https://huggingface.co/facebook/tribev2
- https://ai.meta.com/research/publications/a-foundation-model-of-vision-audition-and-language-for-in-silico-neuroscience/
- https://aidemos.atmeta.com/tribev2/
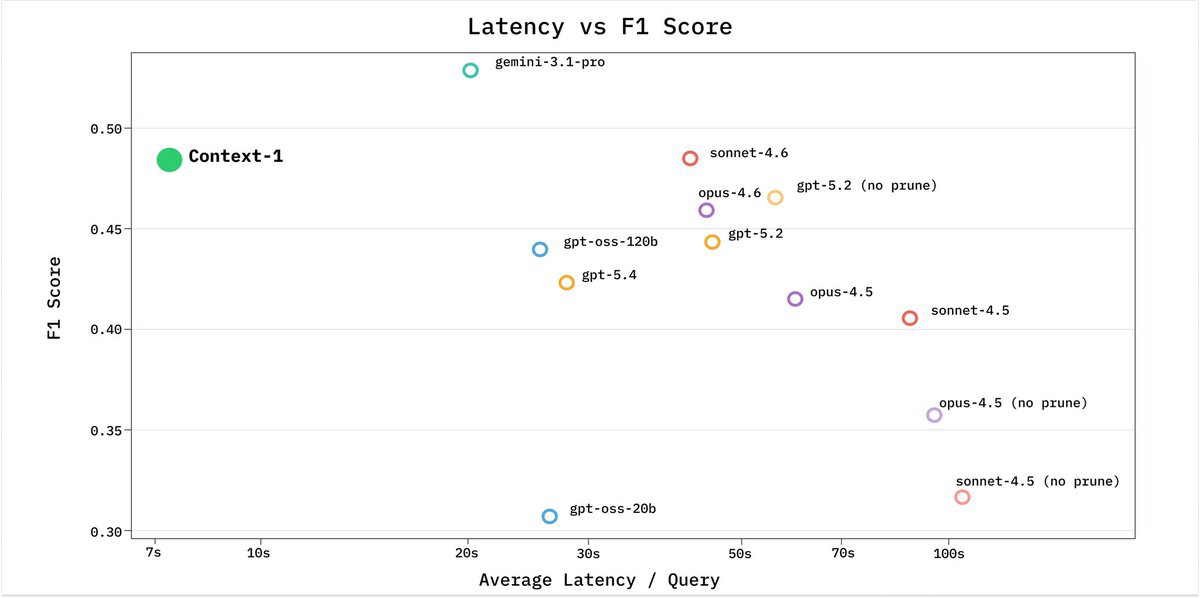
Chroma 发布 200 亿参数 Context-1,开源 agentic 搜索模型 #7
Chroma发布了名为 Context-1 的 200亿参数 开源
Agentic搜索模型。它作为检索子智能体,能以更低的成本和延迟辅助前沿推理模型完成复杂搜索。
Chroma 发布并开源了 agentic search 模型 Context-1,该模型基于 gpt-oss-20b 训练,参数量达 200 亿(基于 MoE 架构),采用 Apache 2.0 协议。
官方称,该模型旨在作为检索 subagent 与前沿推理模型协同,通过分离搜索与生成解决长轨迹成本及延迟问题。
该模型必须运行在特定的 agent harness 中才能复现官方评估结果,官方计划在未来发布完整的 agent harness 和评估代码。
相关链接:
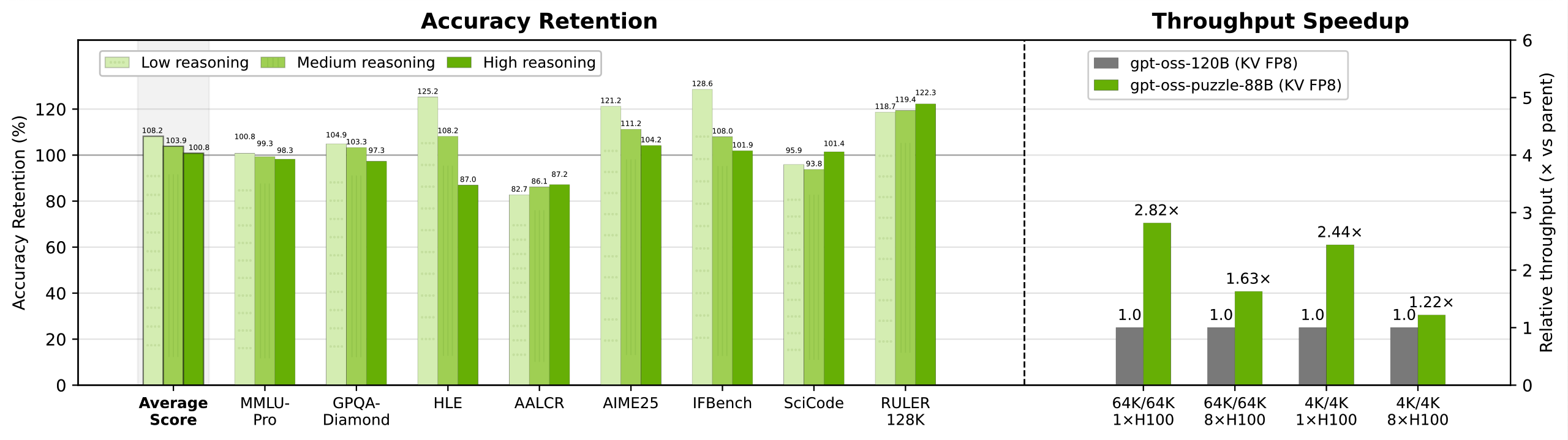
英伟达发布 gpt-oss-puzzle-88B 剪枝量化模型 #8
NVIDIA发布了专为 H100 硬件优化的
gpt-oss-puzzle-88B推理模型,通过异构 MoE 剪枝和MXFP4量化技术,在保持高准确率的同时,将单卡吞吐量最高提升 2.82 倍。
NVIDIA 发布部署优化模型 gpt-oss-puzzle-88B,基于 OpenAI 的 gpt-oss-120b 构建。
该模型采用 Puzzle 神经架构搜索及异构 MoE 剪枝技术,专为缓解 H100 硬件 KV-cache 瓶颈设计。
根据官方数据,其在 8×H100 长上下文场景下吞吐量提升 1.63 倍,单卡提升高达 2.82 倍,准确率匹配或略超父模型。
模型参数量约 88B,支持 128K 上下文。
相关链接:
智谱向所有 GLM Coding Plan 用户开放 GLM-5-Turbo 模型 #9
智谱宣布 GLM-5-Turbo 模型现已面向涵盖 max、pro 及 lite 的全量 GLM Coding Plan 用户开放,并在 4月底前 提供非高峰期 1倍抵扣 的限时福利。
用户需在相关工具配置中手动将模型指定为
glm-5-turbo方可调用。
智谱宣布,基于用户好评及新增计算资源,已面向全量 GLM Coding Plan 套餐用户(涵盖 max、pro 及 lite)开放 GLM-5-Turbo 模型。
在计费方面,该模型常规额度消耗系数与 GLM-5 相同。每日 14:00~18:00 高峰期按 3 倍抵扣,非高峰期按 2 倍抵扣。此外,智谱推出限时福利,非高峰期调用仅作 1 倍抵扣,持续至 4 月底。
用户需在 Coding Agent 自定义配置中手动指定该模型。

Codex 上线 Plugins 插件功能 #10
Codex 上线了 Plugins 插件功能,该功能能把技能与
Slack、Figma等常用工具打包实现无缝认证,让系统不仅能写代码,还能直接执行编码前的规划、研究和协调等工作流。
OpenAI 正式宣布在 Codex 中推出 Plugins 功能,现已在 App、CLI 及 IDE 扩展上线。官方称,该功能是可复用工作流的可安装捆绑包,打包技能、应用集成及 MCP server 配置,支持 Slack、Figma 等工具无缝认证。
开发者可通过目录、CLI 等方式安装,支持本地 marketplace.json 管理,官方公开目录即将推出。
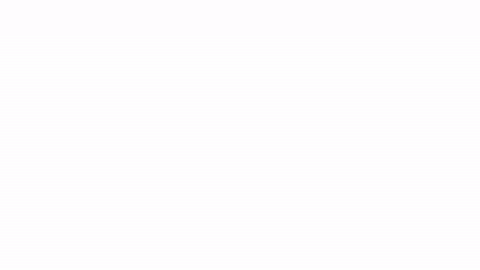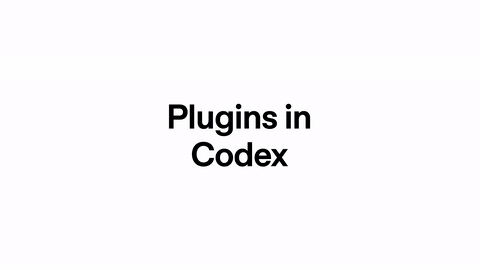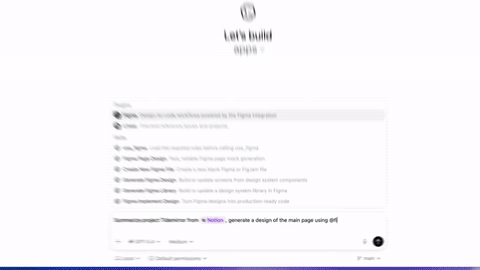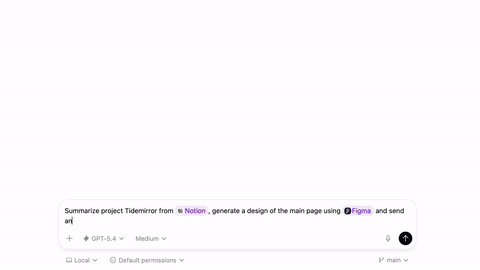
相关链接:
Claude Code 推出云端 auto-fix 功能,支持 PR 自动化修复 #11
Claude Code 推出云端
auto-fix功能,可自动修复代码合并请求的CI检查失败及评审评论。实现合并请求全生命周期的无人值守管理。
Claude 宣布为 Claude Code 推出云端 auto-fix 功能,支持 Web 与移动端异步处理 PR 任务。
根据官方文档,该功能通过订阅 GitHub 事件,允许 Agent 远程自动修复 CI 失败及评审评论,旨在实现 PR 全生命周期自动化。
用户可通过网页版状态栏、移动端指令或粘贴 PR 链接开启。

相关链接:
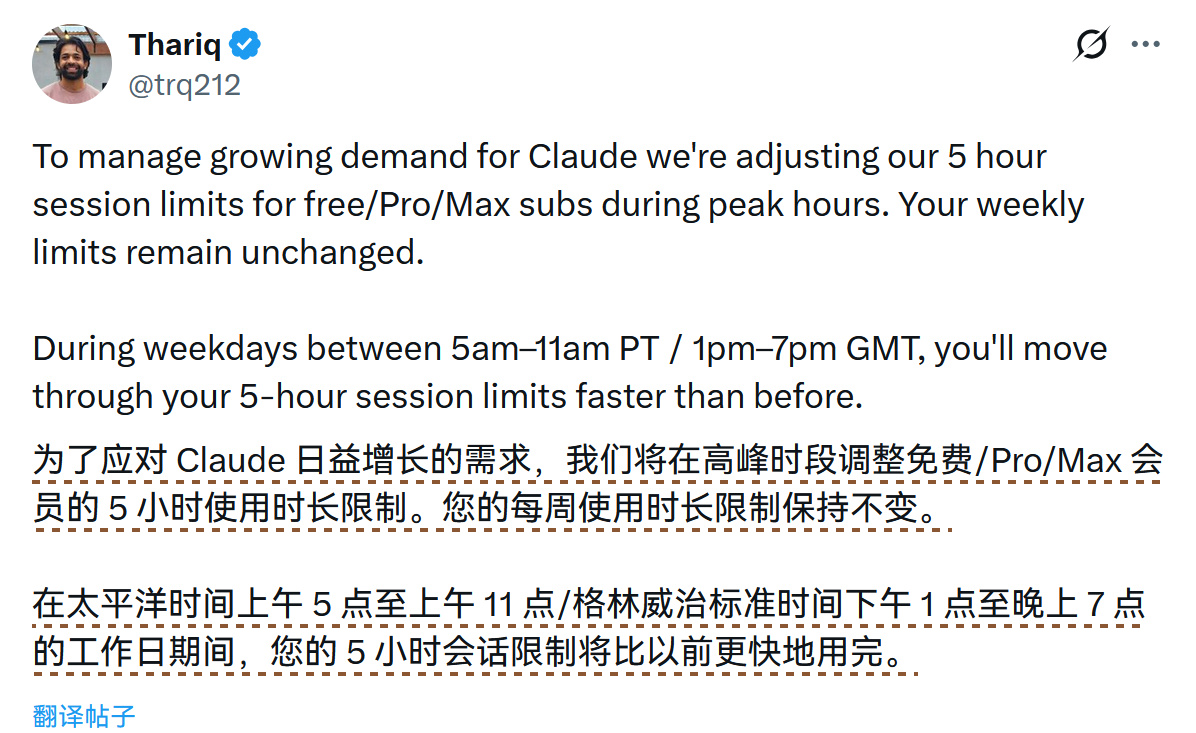
Anthropic 调整 Claude 高峰限制 #12
Anthropic 宣布加快了 Claude 在工作日高峰时段的会话配额消耗速度,每周总限制保持不变。
Anthropic 官方人员 Thariq 宣布调整 Free、Pro 及 Max 订阅在工作日高峰时段的 5 小时会话限制。
调整后,用户在工作日太平洋时间上午 5 点至上午 11 点(北京时间晚上 9:00 – 次日凌晨 3:00)期间,消耗会话限制的速度将比以往更快。
官方表示,用户的每周总限制保持不变。
相关链接:
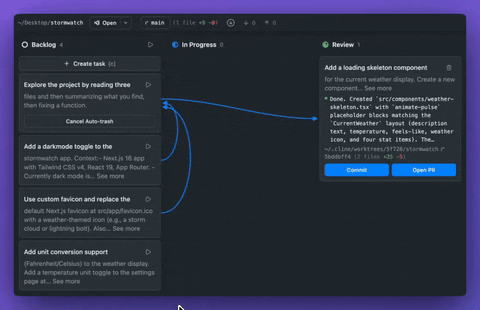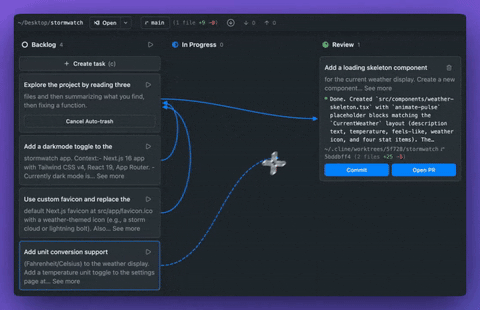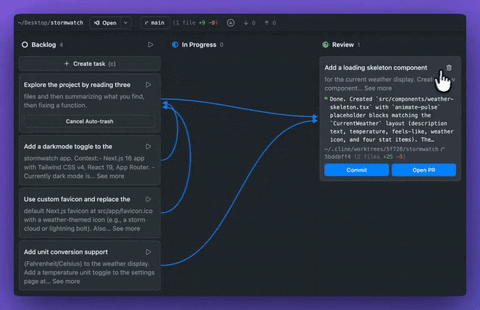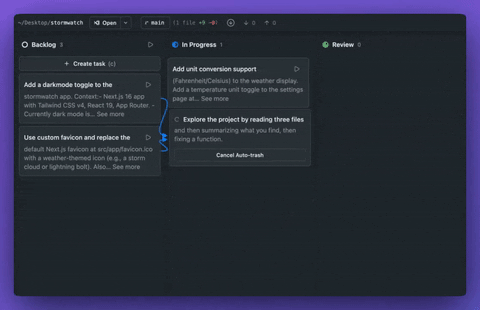
Cline 推出 Cline Kanban,开源多 Agent 编排工具 #13
Cline官方发布了免费开源的多Agent编排工具 Cline Kanban。该工具通过
git worktrees实现任务隔离与依赖链管理,能自动拆分项目以实现并行处理,兼容Claude Code等多种 CLI Agent。
Cline 官方宣布推出免费开源应用 Cline Kanban,无需账号且支持 CLI-agnostic 多 Agent 编排。该应用通过 npm i -g cline 安装后在本地 127.0.0.1 启动 Web App,兼容 Claude Code、Codex 和 Cline 等 CLI Agent。
其核心机制是让任务在 git worktrees 中隔离运行,内置侧边栏 Agent 自动拆分大项目并创建依赖链以实现最大并行化。
该应用内置完整 Git 界面,支持不离页执行分支切换及代码推送等操作。
Gemini 新增功能支持导入其他 AI 应用记忆及聊天记录 #14
Google今日在Gemini的Web端上线了全新工具,允许普通用户通过跨应用复制提示词生成结果或上传ZIP文件,直接将其他AI的记忆偏好或历史聊天记录导入Gemini。
该功能让用户体验更流畅,无需手动重写或重新配置,即可迁移此前在其他平台使用过的
AI模型交互习惯与上下文偏好。
Google 官方宣布 Gemini 应用推出全新的导入功能,允许所有消费者账户用户将其他 AI 应用中的记忆、偏好和聊天记录直接导入 Gemini,从而无需从零开始。
该功能包含记忆导入和聊天记录导入两部分:前者通过在设置中复制提示词至其他 AI 应用获取偏好摘要并粘贴回 Gemini 实现,使其能够理解用户的关键偏好、人际关系和个人背景;后者支持直接上传其他 AI 提供商导出的聊天记录 ZIP 文件,以便用户无缝衔接和搜索过往对话。
这两项功能今日起开始在 Web 端设置页面推出,并即将登陆移动端。
相关链接:
Google Search Live 功能扩展至全球,覆盖超 200 个国家和地区 #15
谷歌宣布将 Search Live 功能扩展至全球 200 多个国家和地区,由全新的
Gemini 3.1 Flash Live模型驱动,支持多语言下的语音与相机实时交互。
Google 正式宣布将 Search Live 功能扩展至全球,覆盖 AI Mode 支持的所有语言和地区,涉及超过 200 个国家和地区。该功能由全新的 Gemini 3.1 Flash Live 音频与语音模型驱动,允许用户在 AI Mode 下通过语音和相机与搜索引擎进行实时交互。
用户可通过 Android 或 iOS 版 Google app 及 Google Lens 启用。此前该功能已在美国以英语正式发布。

相关链接:
Google 翻译耳机实时翻译登陆 iOS,适用范围扩至七国 #16
Google 翻译的“耳机实时翻译”功能正式登陆 iOS 平台,并扩展至日本、英国等更多国家。用户只需连接任意耳机并在应用内点击启用,即可在 70 多种语言间进行实时翻译。
Google Translate 的 "Live translate with headphones" 功能正式登陆 iOS 平台,并在 iOS 和 Android 端扩展至法国、德国、意大利、日本、西班牙、泰国和英国。该功能支持 70 多种语言,用户连接任意耳机后,在应用中点击 "Live translate" 即可体验实时翻译。根据官方介绍,该技术能够保留原始说话者的语气和语调。
相关链接:
林俊旸发文:认知模式将转向 Agentic Thinking #17
Qwen 团队前负责人林俊旸发文称,AI 模型的认知模式正从单纯的“推理思维”向能与环境交互的
Agentic Thinking发生深刻转变。未来的核心竞争力将从RL算法转向环境构建与Harness工程,以解决模型获得工具权限后的“奖励作弊”挑战。
Qwen 前负责人林俊旸发文称,AI 模型的认知模式正从“推理思维”向“Agentic Thinking”发生深刻转变。
过去两年中,OpenAI 的 o1 展示了“思维”可以作为一项被训练并暴露给用户的一等能力,DeepSeek-R1 则证明了推理风格的训练后处理能够在原始实验室之外被复现和扩展,这推动了从扩展预训练向扩展推理训练后处理的首次重大过渡。
Anthropic 围绕 Claude 3.7 和 Claude 4 所强调的受工作负载塑造、允许工具交织的集成推理,提供了一种有益的纠正,标志着行业正从“训练模型”转向“训练 Agent”。
与追求内部思考质量的推理思维不同,Agentic Thinking 的核心在于模型在与环境交互时维持有效行动的能力。这要求 RL 基础设施实现训练与推理的深度解耦,并使环境本身成为关注稳定性、真实性和抗利用性的一流研究产物。
该人士进一步预警,随着模型获得工具访问权限,奖励作弊将成为 Agent 时代最棘手的挑战。未来的核心竞争力将从 RL 算法转向更好的环境构建、更紧密的训练服务集成以及 Harness 工程。
相关链接:
Cursor 发布 Composer 2 报告,披露基于 Kimi K2.5 训练细节 #18
Cursor 发布了 Composer 2 技术报告,该模型基于
Kimi K2.5打造,引入了“实时强化学习”机制。通过将生产环境中的真实用户反馈直接用于训练,实现了最快每 5 小时一次的模型迭代。
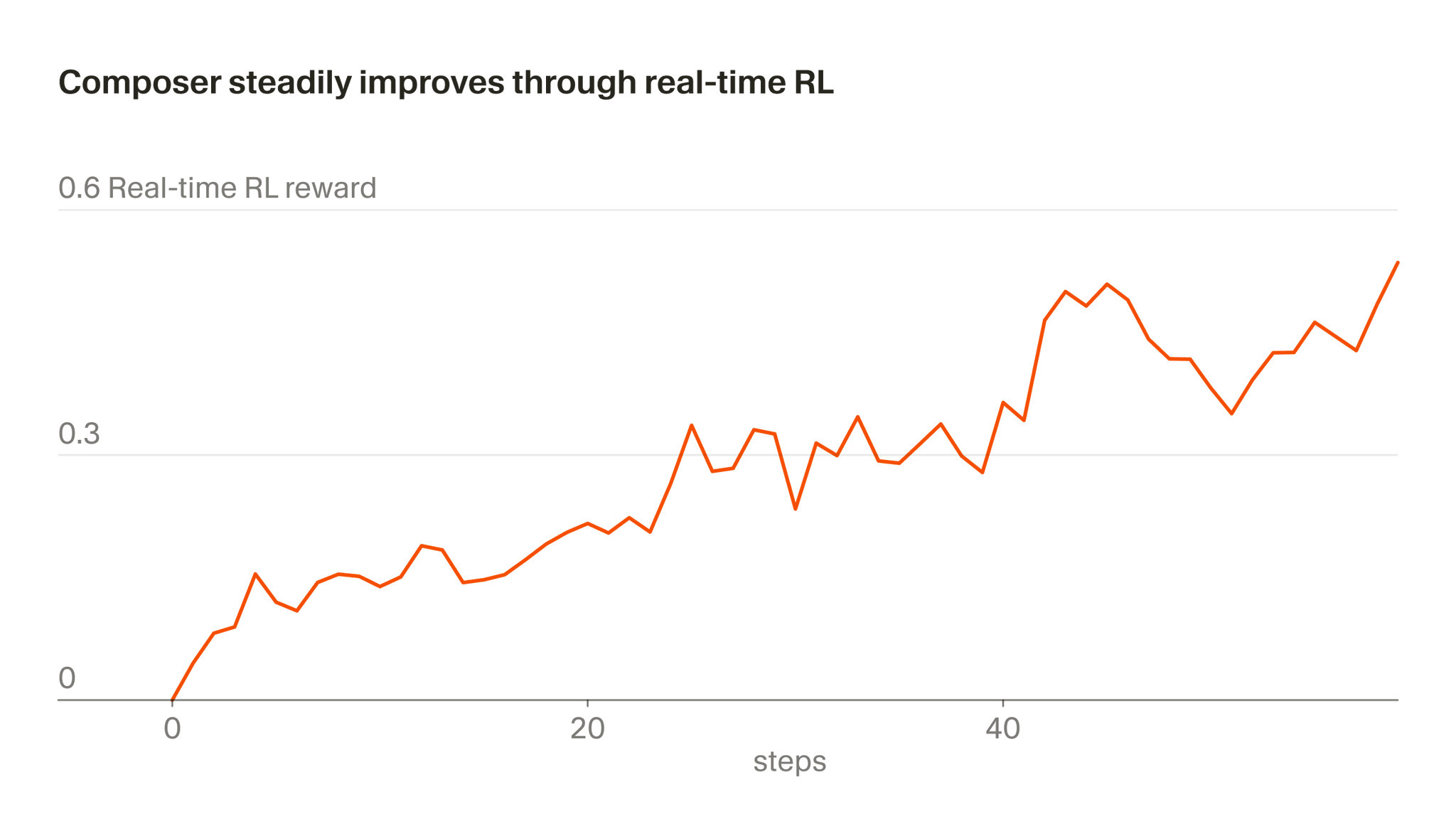
Cursor 近期发布 Composer 2 技术报告,披露其面向 agentic software engineering 专用模型的训练细节。该模型以 Kimi K2.5(1.04T 总参数,32B active 参数的 MoE 模型)为基座,通过 continued pretraining 与大规模 reinforcement learning 两阶段训练。
预训练阶段将长上下文扩展至 256k token,并引入 Multi-Token Prediction 层支持 speculative decoding;RL 阶段采用改进的 Dr. GRPO policy gradient 方案,结合 self-summarization 技术与辅助奖励机制。
官方博客还介绍了“实时 RL”方法,将模型部署至生产环境,以真实用户交互为奖励信号,最快每五小时发布一次改进版本。A/B 测试显示,该方法使编辑保留率提升 2.28%,用户不满消息减少 3.13%,延迟降低 10.3%。
相关链接:
KwaiKAT 宣布品牌焕新,确认 KAT-Coder-Pro V2 即将发布 #19
快手 KwaiKAT 团队宣布基于未来战略规划进行品牌焕新,同时确认新的旗舰模型
KAT-Coder-Pro V2即将发布。
KwaiKAT 官方近日宣布,基于对未来发展规划的预期调整,实施品牌焕新计划,并同步确认新一代产品 KAT-Coder-Pro V2 即将发布。

相关链接:
特朗普任命 PCAST 首批成员,黄仁勋扎克伯格入选 #20
美国总统特朗普正式任命了总统科技顾问委员会的首批成员,成员名单囊括了英伟达CEO黄仁勋、Meta CEO扎克伯格、谷歌联合创始人布林等13位顶级科技领袖。该委员会将重点针对AI政策及科技监管提供核心建议。
美国总统特朗普宣布任命其总统科技顾问委员会(PCAST)的首批成员。该委员会由行政令设立,最多可由24名成员组成,旨在将美国最杰出的科技界领军人物聚集在一起,就加强美国在科技领域的领导地位向总统提供建议。
首批获任命的13名成员包括 Marc Andreessen、Sergey Brin、Safra Catz、Michael Dell、Jacob DeWitte、Fred Ehrsam、Larry Ellison、David Friedberg、Jensen Huang、John Martinis、Bob Mumgaard、Lisa Su 和 Mark Zuckerberg。
相关链接:
月之暗面据称考虑赴港 IPO #21
据彭博社引述知情人士消息报道,Kimi的开发商月之暗面正考虑赴港IPO。据称,该公司已与中金公司及高盛集团就潜在IPO事宜进行过磋商,但具体时间与最终是否推进均尚不确定。
据彭博社引述知情人士消息,北京人工智能公司月之暗面正考虑赴港 IPO,处于早期阶段。
该公司已与中金公司及高盛集团磋商,但具体时间与是否推进尚不确定,各方均未正面回应。
据相关报道,该公司近期寻求筹集至高 10 亿美元,估值约 180 亿美元。
今年早些时候,其已获逾 7 亿美元融资。
相关链接:
据传苹果蒸馏Gemini以优化自研端侧模型 #22
据报道,Apple与Google的AI合作深度远超预期,Apple不仅拥有对Google Gemini模型的完全访问权限,并正通过从Gemini“蒸馏”提升其自研端侧模型表现。
据媒体报道,Apple 与 Google 的 AI 合作深度超预期,前者在其数据中心拥有 Google Gemini 模型完全访问权限。
知情人士透露,Apple 正利用“蒸馏”技术,让外部模型学习 Gemini 的内部计算过程与“思维链”,旨在生成能在 iPhone 等设备端运行的小型模型,降低算力需求与成本。
相关链接:
提示:内容由AI辅助创作,可能存在幻觉和错误。