2026-02-24

AI 早报 2026-02-24
概览
模型发布
开发生态
- OpenAI Responses API 新增 WebSocket 模式 ↗
#3 - Google 回应封禁滥用 Antigravity 的 Gemini 订阅用户 ↗
#4 - Anthropic 推广 COBOL 代码自动化迁移方案 ↗
#5
产品应用
行业动态
- Anthropic 指控三家中国 AI 实验室进行工业级模型蒸馏攻击 ↗
#8 - 五角大楼考虑终止与 Anthropic 的 AI 军事合同 ↗
#9 - OpenAI 联手四大咨询巨头 组建 Frontier 企业 AI 联盟 ↗
#10 - 月之暗面 Kimi 近20天收入超2025全年 ↗
#11 - Google for Education 为美国教育工作者免费提供 Gemini AI 培训 ↗
#12
技术与洞察
前瞻与传闻
- xAI 即将推出 Grok 4.20 Beta 2 以修复低级错误 ↗
#15
OpenAI 在 Realtime API 中上线 gpt-realtime-1.5 语音模型 #1
OpenAI已在Realtime API中正式上线
gpt-realtime-1.5模型,该模型在音频平滑度、指令遵循、工具调用及多语言处理准确性等方面均有显著提升。
OpenAI 在其 Realtime API 中引入了最新的 gpt-realtime-1.5 模型。该模型专注于端到端语音交互体验的优化。据官方介绍,新模型在音频输出平滑度、指令遵循准确性、工具调用稳定性以及多语言处理能力上均有显著提升,能提供更自然的语音反馈,并更精准地执行用户指令和触发外部工具。目前,gpt-realtime-1.5 已正式上线供开发者调用。

相关链接:
- https://x.com/OpenAIDevs/status/2026014334787461508
- https://x.com/pbbakkum/status/2025998657187991818
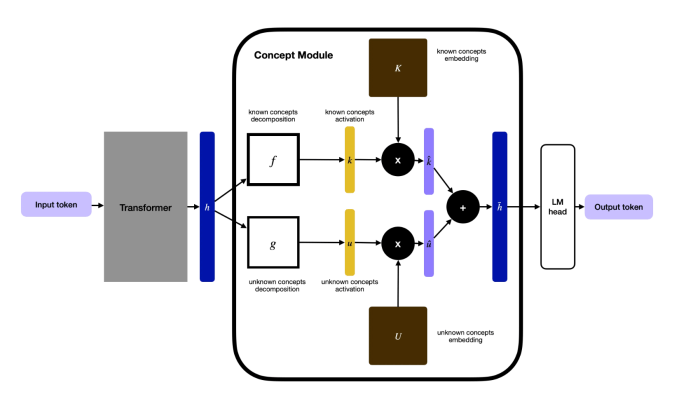
Guide Labs 推出可解释因果扩散语言模型 Steerling-8B #2
Guide Labs 发布了 80 亿参数的可解释因果扩散语言模型
Steerling-8B,该模型支持非自回归生成,允许开发者对预测结果进行概念层面的归因与干预。
Guide Labs发布80亿参数的可解释因果扩散语言模型Steerling-8B。该模型融合掩码扩散与概念分解技术,支持非自回归生成及概念层面的归因与干预。目前代码已在GitHub开源,权重已上传Hugging Face。
技术上,模型采用块因果注意力架构,上下文长4096,基于1.35万亿Token训练。官方计划未来发布技术报告及API服务,商业用途需单独联系。
相关链接:
- https://github.com/guidelabs/steerling
- https://huggingface.co/guidelabs/steerling-8b
- https://techcrunch.com/2026/02/23/guide-labs-debuts-a-new-kind-of-interpretable-llm
OpenAI Responses API 新增 WebSocket 模式 #3
OpenAI 在 Responses API 中正式引入了
WebSocket模式,该模式将长链条任务的执行速度提升了约 40%。
OpenAI 在 Responses API 中推出 WebSocket 模式,专为低延迟及高频工具调用的 Agent 任务设计。该模式通过持久连接仅传输增量数据,在包含 20 次以上工具调用的场景中,执行速度较传统 HTTP 提升约 40%。其核心利用连接本地内存缓存实现快速响应,并兼容零数据保留(ZDR)策略。

相关链接:
- https://developers.openai.com/api/docs/guides/websocket-mode
- https://x.com/TheRealAdamG/status/2026029238785036552
Google 回应封禁滥用 Antigravity 的 Gemini 订阅用户 #4
Google 因 Antigravity 后端遭恶意滥用,对部分通过 OAuth 使用
OpenClaw调用Gemini模型的 AI Pro 和 Ultra 订阅用户实施了封禁。Antigravity 官方团队成员表示,后续将开放合规用户的申诉渠道。目前,OpenClaw已计划移除相关支持。
Google 针对 Antigravity 后端遭大规模滥用,封禁了多名通过 OAuth 使用 OpenClaw 使用 Gemini 的 AI Pro/Ultra 订阅用户。Antigravity 官方成员 Varun Mohan 表示,此举旨在保障服务质量与真实用户权益,后续将开放合规用户申诉通道。OpenClaw 开发者批评 Google 手段严苛并表示将移除相关支持。

相关链接:
Anthropic 推广 COBOL 代码自动化迁移方案 #5
Anthropic 发布文章,介绍可利用
Claude Code攻克 COBOL 遗留系统迁移难题,导致 IBM 股价暴跌。
Anthropic 发布《Code Modernization Playbook》并推广其 agentic coding 工具 Claude Code,指其能自动化 COBOL 语言的现代化改造。COBOL 诞生于 1959 年,目前支撑着美国约 95% 的 ATM 交易,全球数千亿行代码仍在金融、航空等关键系统中运行。
此举引发市场震动,市场将 Claude Code 定位为解决大型机遗留系统迁移成本瓶颈的方案,导致 IBM 股价在 2026 年 2 月 23 日跌幅达 13.2%,创下多年来的单日最大百分比跌幅。

相关链接:
Gemini 上线视频模板功能 #6
Google Gemini 在网页端和 App 端上线了基于
Veo 3.1模型的视频模板功能。用户可直接套用 15 种预设风格生成视频。
Google Gemini 升级视频生成功能,引入基于 Veo 3.1 的预设模板,旨在简化创作流程,现已于网页端及 App 上线。用户通过“Create video”可选用 15 种风格模板,并结合图文进行深度自定义,支持原生 9:16 画幅。
相关链接:
- https://x.com/GeminiApp/status/2026001595708866759
- https://9to5google.com/2026/02/23/gemini-video-templates/
openclaw 发布 2026.2.22 版本 #7
openclaw发布了2026.2.22版本,新增了对
Mistral提供商的支持,涵盖内存嵌入与语音功能,并引入了原生Synology Chat插件。
openclaw 发布 2026.2.22 版本。此次更新新增 Mistral 提供商支持、Synology Chat 插件及可选的内置自动更新器。功能上,优化了多语言内存检索,重构 Browser 扩展以提升连接稳定性,支持 Cron 任务并行执行,并改善了 Webchat 渲染性能。安全方面集成 40 余项硬化修复,涵盖敏感数据脱敏、Exec 环境隔离、SSRF 防护及入站媒体限制。同时,该版本调整了 WSL2 与 Node22 兼容性,优化 OpenRouter 提示词缓存,并修复了 Docker 部署权限问题。
相关链接:
Anthropic 指控三家中国 AI 实验室进行工业级模型蒸馏攻击 #8
Anthropic 发布技术报告指控 DeepSeek、月之暗面 与 MiniMax 合计利用约 2.4 万个 账号对 Claude 模型发起模型蒸馏,累计产生超过 1600 万次 交互,以获取 Agent 推理及编程等核心能力。Anthropic 称已通过行为指纹识别等手段加强防御。
Anthropic 发布报告指控 DeepSeek、月之暗面 及 MiniMax 对 Claude 发起工业级蒸馏攻击。三家实验室利用约 2.4 万个虚假账号及代理网络绕过地区限制,产生超 1600 万次交互,非法提取 Agent 推理、编程等核心能力。其中,MiniMax 规模最大(超 1300 万次),月之暗面 涉及推理轨迹提取(超 340 万次),DeepSeek 则聚焦逻辑与审查规避(约 15 万次)。
Anthropic 认为此举违反服务条款,规避出口管制并导致模型安全护栏失效,构成安全风险。目前,Anthropic 正通过流量分类、行为指纹及情报共享等措施强化防御,以降低模型被蒸馏的有效性。

相关链接:
- https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks
- https://x.com/AnthropicAI/status/2025997928242811253
五角大楼考虑终止与 Anthropic 的 AI 军事合同 #9
五角大楼正因 AI 安全限制谈判陷入僵局而考虑终止与 Anthropic 的合作,国防部长 Pete Hegseth 已定于 2026年2月24日 召见 Anthropic CEO,要求其取消对军事用途的限制。
五角大楼正在审议与人工智能公司 Anthropic 的合作关系,并考虑在双方关于 AI 使用安全限制的长期谈判陷入僵局后终止合同。国防部长 Pete Hegseth 已传唤 Anthropic CEO Dario Amodei 于 2026 年 2 月 24 日 前往五角大楼参会,旨在就 AI 模型的军事化使用条款发出最后通牒。目前,Anthropic 的 Claude 模型是五角大楼分级网络中唯一可用的前沿模型,双方核心矛盾在于 Anthropic 拒绝取消针对“大规模监控”与“全自主武器”的使用限制。
在技术与合同层面,Anthropic 于 2025 年夏天 与五角大楼签署了最高价值 2 亿美元 的合同,其 Claude 是首个且唯一进入军方分级网络的前沿模型。
针对僵局,五角大楼已提出可能将 Anthropic 标记为“供应链风险”,该定性将废止现有合同并强制所有承包商剔除 Claude。尽管军方评估认为短期内完全替换 Claude 存在难度,但已考虑制定替换方案。
相关链接:
- https://www.axios.com/2026/02/23/hegseth-dario-pentagon-meeting-antrhopic-claude
- https://www.axios.com/2026/02/19/anthropic-pentagon-ai-fight-openai-google-xai
OpenAI 联手四大咨询巨头 组建 Frontier 企业 AI 联盟 #10
OpenAI 宣布与 BCG、麦肯锡、埃森哲 及 凯捷 达成 “Frontier Alliances” 合作,旨在利用 Frontier 平台协助企业规模化部署
AI Coworkers。这一模式由 OpenAI 提供构建Agent的技术底座,合作伙伴提供战略与系统集成服务,共同解决企业AI难以从试点转化为实际生产价值的痛点。
OpenAI 官方宣布推出 “Frontier Alliances” 合作计划,与 Boston Consulting Group (BCG)、McKinsey & Company、Accenture 和 Capgemini 建立多年期合作伙伴关系,旨在协助企业利用 Frontier 平台在全球范围内部署 AI Coworkers。OpenAI 认为,企业从 AI 中获取价值的限制因素通常不在于模型智能,而在于 Agent 在组织内的构建和运行方式。此次合作旨在解决企业难以将 AI 从试点阶段转化为实际生产价值的痛点,OpenAI 提供构建和运行 AI 的技术基础 Frontier 平台,合作伙伴则负责提供战略制定、工作流重设计、系统集成及变革管理服务。目前 Frontier 平台仅向有限客户开放,预计未来几个月将扩大可用范围。

相关链接:
- https://openai.com/index/frontier-alliance-partners/
- https://openai.com/index/introducing-openai-frontier/
月之暗面 Kimi 近20天收入超2025全年 #11
据报道,月之暗面此前发布的
K2.5大模型驱动Kimi近20天收入超越去年全年,增长动力来自全球付费用户及API调用量大幅提升,且海外收入已反超国内。
据澎湃新闻报道,大模型独角兽 月之暗面 估值突破 100亿美元。据知情人士透露,Kimi 近 20 天收入已超 2025 年全年,海外收入超国内,增长由全球付费用户及 API 调用量驱动。媒体报道称,该公司即将完成由 阿里、腾讯 等领投的超 7亿美元 新融资。
相关链接:
Google for Education 为美国教育工作者免费提供 Gemini AI 培训 #12
Google for Education 宣布,将在未来几个月内面向全美教职员工推出免费的 Gemini 综合培训,帮助教育工作者学习利用
Gemini和NotebookLM辅助生成教学材料。
Google for Education 与 ISTE+ASCD 宣布合作,将推出全美规模最大的免费 Gemini 综合培训计划。该计划旨在赋能 600 万 名 K-12 及高等教育教职员工,帮助其及所服务的超 7400 万 名学生安全、有效地使用 Gemini 和 NotebookLM。
培训模块由教育工作者构建,简短灵活,涵盖创建个性化课程、调整教学材料及使用 NotebookLM 辅助学习等现实用例。完成培训者将获微证书或徽章,内容符合 ISTE+ASCD 标准。官方博客显示,该计划将在未来几个月内推出,现已开放意向登记。

相关链接:
- https://blog.google/products-and-platforms/products/education/teacher-ai-literacy-training/
- https://docs.google.com/forms/d/e/1FAIpQLSejyQW_BNSrpCS-7XTF6cKuCjIJCFb9Zg-dz7rXh_iE-sD4xw/viewform
- https://edu.google.com/intl/ALL_us/
OpenAI 宣布停用 SWE-bench Verified 指标 #13
OpenAI 宣布停止使用
SWE-bench Verified指标来评估前沿模型,并建议全行业转向SWE-bench Pro。理由是旧基准存在严重的测试用例缺陷和训练数据污染,导致模型能够直接“背诵”答案,评分也趋于饱和。
OpenAI宣布停止使用 SWE-bench Verified 指标,建议行业转向 SWE-bench Pro。技术分析显示,该基准因测试用例缺陷及训练数据污染,已无法准确衡量模型真实进展。审计发现 59.4% 的被测问题存在测试设计缺陷,导致正确代码被拒;红蓝对抗实验证实多款前沿模型存在强污染,能复现原始修复方案。目前,OpenAI已改用 SWE-bench Pro,并建议未来评估需严格执行污染测试、优化自动化评分及投资私有基准测试。

相关链接:
Anthropic 发布 AI 流畅度指数报告 #14
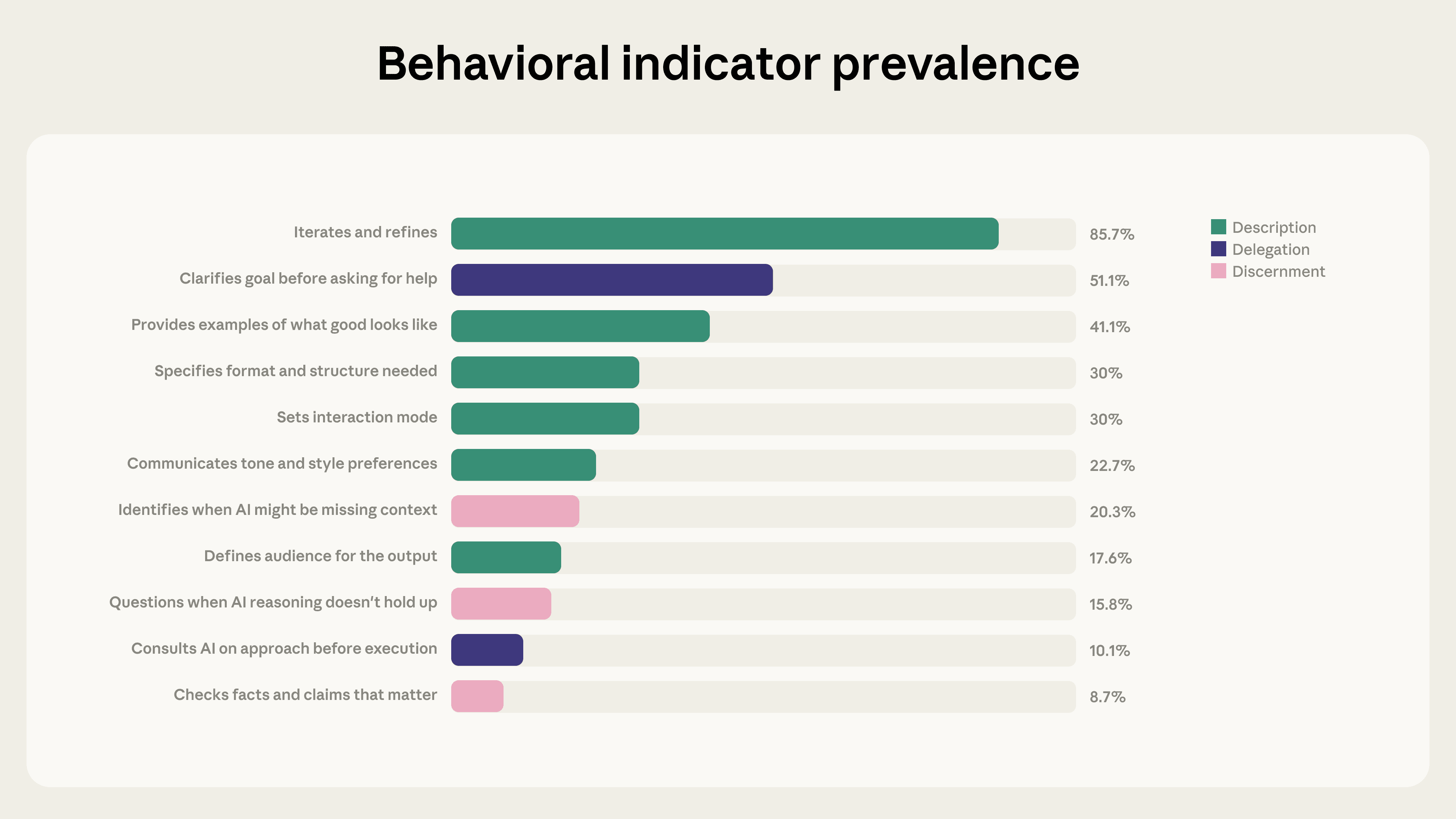
Anthropic 发布“AI 流畅度指数”报告,通过量化指标衡量用户与 AI 协作的熟练程度。研究发现,尽管 85.7% 的用户具备反复迭代的良好协作习惯,但在处理代码或文档等结构化内容时,用户普遍因成品看似完备而产生评估盲区,导致对输出结果的审查意愿显著下降。
Anthropic 发布《AI 流畅度指数》报告,旨在量化人机协作熟练度。该研究基于 4D AI Fluency Framework,选取 11 项可观测指标,分析了 2025 年 1 月的 9830 个匿名对话样本。数据显示,85.7% 的用户具有“迭代与完善”习惯,协作把控力更强,但仅 30% 会设定明确协作条款。针对 Artifacts(代码或文档)的研究发现,用户虽指令更详尽,却因作品完备感导致审查意愿下降,存在评估盲区。此外,跨语言与时间测试显示数据稳定。Anthropic 计划后续开展同类群组分析及定性研究以弥补现有局限。
相关链接:
xAI 即将推出 Grok 4.20 Beta 2 以修复低级错误 #15
xAI 计划本周推出
Grok 4.20 Beta 2,重点修复前一版本中的各类问题。
xAI计划本周推出 Grok 4.20 Beta 2,重点修复前一版本中的各类问题。官方尚未公布正式版时间表,有关配额调整、自定义提示词及独立应用等细节亦未披露。


相关链接:
提示:内容由AI辅助创作,可能存在幻觉和错误。
作者橘鸦Juya,视频版在同名哔哩哔哩。欢迎点赞、关注、分享。