2026-04-24

AI 早报 2026-04-24
概览
要闻
- OpenAI 发布 GPT-5.5 和 GPT-5.5 Pro 模型 ↗
#1 - Anthropic 承认 Claude Code 质量下降并重置用户额度 ↗
#2 - 腾讯混元发布并开源 Hy3 preview 模型 ↗
#3
模型发布
- 蚂蚁百灵发布 Ling-2.6-1T 模型,提供试用并计划开源 ↗
#4 - 蚂蚁集团开源 LLaDA2.0-Uni 统一多模态模型 ↗
#5 - 小米 MiMo 发布语音模型系列,8B 参数 ASR 开源 ↗
#6 - xAI 发布语音模型 grok-voice-think-fast-1.0 ↗
#7 - 字节跳动发布 Seed3D 2.0,几何纹理生成达 SOTA 表现 ↗
#8
开发生态
产品应用
- Claude 桌面端被发现支持配置第三方大语言模型接口 ↗
#11 - Claude 桌面端支持 URL 协议唤起特定会话及文件 ↗
#12 - Claude 扩展 Connectors,新增 15 款日常生活应用 ↗
#13 - OpenAI 发布 ChatGPT for Clinicians ,推出 HealthBench 评测基准 ↗
#14 - Gemini 推出对话分支功能,逐步推送中 ↗
#15 - NotebookLM 优化多人分享流程,新增支持断点续学 ↗
#16 - OpenClaw 发布 2026.4.22 版,扩展多模型与语音支持 ↗
#17
技术与洞察
- Google DeepMind 提出 Vision Banana 模型,视觉任务达最优水平 ↗
#18 - Google DeepMind 提出 Decoupled DiLoCo 架构,支持低带宽跨区大模型训练 ↗
#19
行业动态
OpenAI 发布 GPT-5.5 和 GPT-5.5 Pro 模型 #1
OpenAI 正式发布了 GPT-5.5 和 GPT-5.5 Pro 模型。GPT-5.5 被官方定位为迄今最智能且最直观易用的版本。
该版本主打
agentic coding、computer use、knowledge work和early scientific research场景。目前这两款模型已在 ChatGPT 上分别向特定付费用户逐步开放。而 GPT-5.5 则在 Codex 中面向所有付费用户开放。模型 API 将在后续上线,其中,GPT-5.5 的定价为每百万输入 token 5美元、输出30美元。
GPT-5.5 Pro 版为输入30美元、输出180美元。
OpenAI发布了GPT-5.5及GPT-5.5 Pro模型,GPT-5.5被官方定位为迄今最智能且最直观易用的版本。
该模型主打 agentic coding、computer use、知识工作与科学研究场景。它在保持与GPT-5.4同等per-token延迟的同时实现智力跃升,并在Codex中显著降低完成同类任务所需的token消耗。
在ChatGPT中,Plus及以上用户可使用GPT-5.5 Thinking,Pro、Business及Enterprise用户则可使用专为高难度与高准确性任务优化的GPT-5.5 Pro。
在Codex中,Plus、Pro、Business、Enterprise、Edu及Go计划用户可使用具备40 万token上下文窗口的GPT-5.5,并可启用快达1.5 倍但成本为2.5 倍的Fast模式。
API即将上线,gpt-5.5将在API中提供100 万token上下文窗口。标准定价为每百万输入token 5 美元、输出token 30 美元。
gpt-5.5-pro的API定价则为每百万输入token 30 美元、输出token 180 美元。
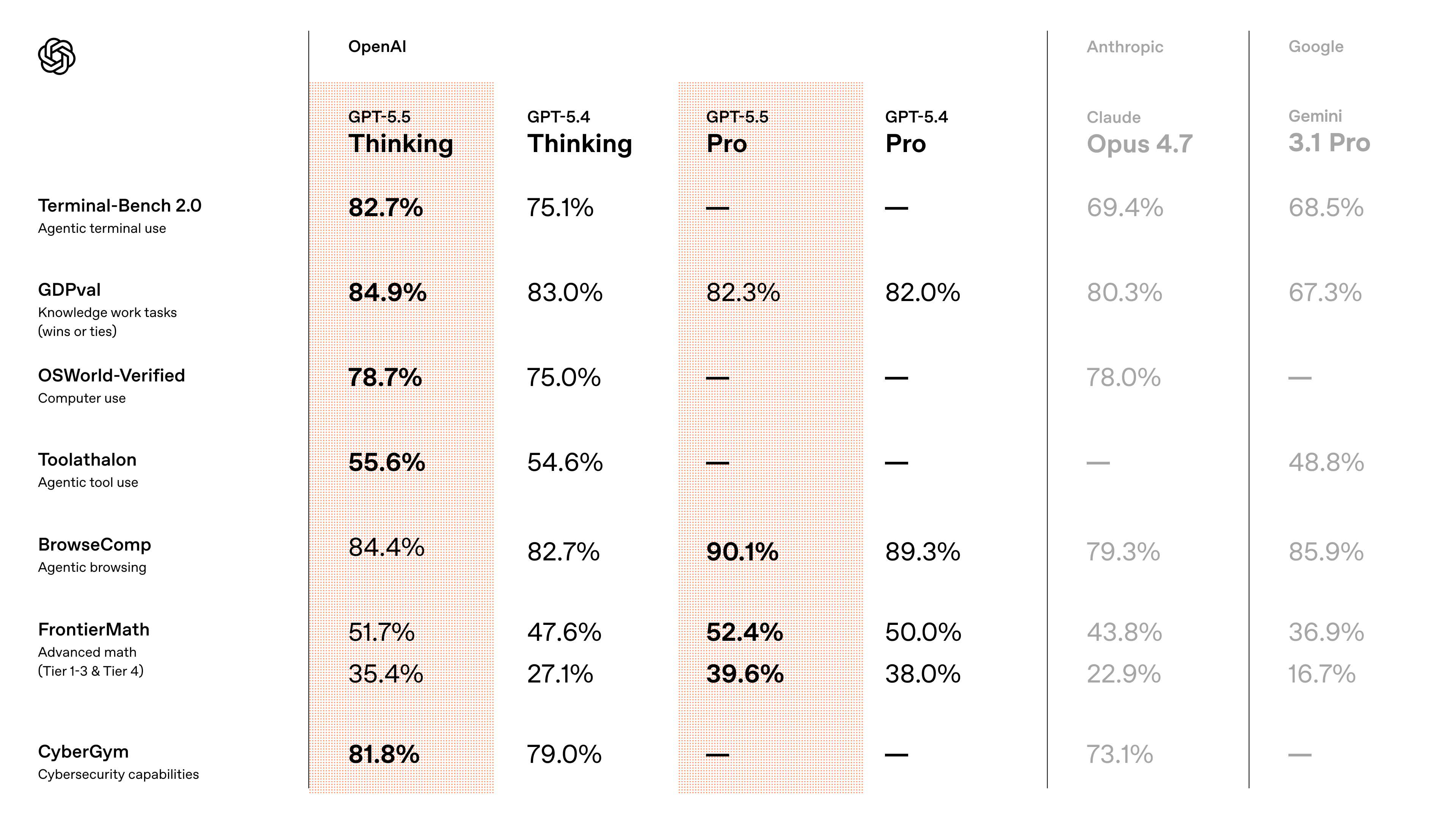
官方测试数据显示,gpt-5.5在Terminal-Bench 2.0、OSWorld-Verified、Toolathlon、FrontierMath Tier 4、CyberGym等多项基准上取得领先成绩。
且OpenAI已将其生物/化学与网络安全能力在内部Preparedness Framework中均评定为“High”级别。同时配套部署了更严格的网络滥用分类器并扩展了Trusted Access for Cyber计划。


相关链接:
Anthropic 承认 Claude Code 质量下降并重置用户额度 #2
Anthropic 发布报告称,用户反馈的 Claude Code 质量下降问题确实存在。
报告指出了导致该问题的三个原因:一是为了降低延迟而下调了模型的默认推理努力程度。二是针对空闲会话的缓存优化存在逻辑缺陷,导致模型丢失了历史推理记忆。
三是为控制冗长输出引入的系统提示词长度限制导致性能下降。目前,上述所有问题已在新版本中全面修复。
Anthropic 官方重置了所有订阅者的额度限制以作补偿,并重申模型和 API 没有受到影响。
Anthropic 官方近期发布了关于 Claude Code 质量下降的事后分析报告,确认该问题由影响 Claude Code、Claude Agent SDK 及 Claude Cowork 的三个独立变更引起,其 API 和推理层均未受到影响。
首先,为降低极长延迟,官方曾将 Sonnet 4.6 和 Opus 4.6 的默认推理努力程度从 high 降至 medium,这导致部分用户感知到模型智能下降,该变更已被撤销,目前 Opus 4.7 的默认努力程度调整为 xhigh,其他模型恢复为 high。
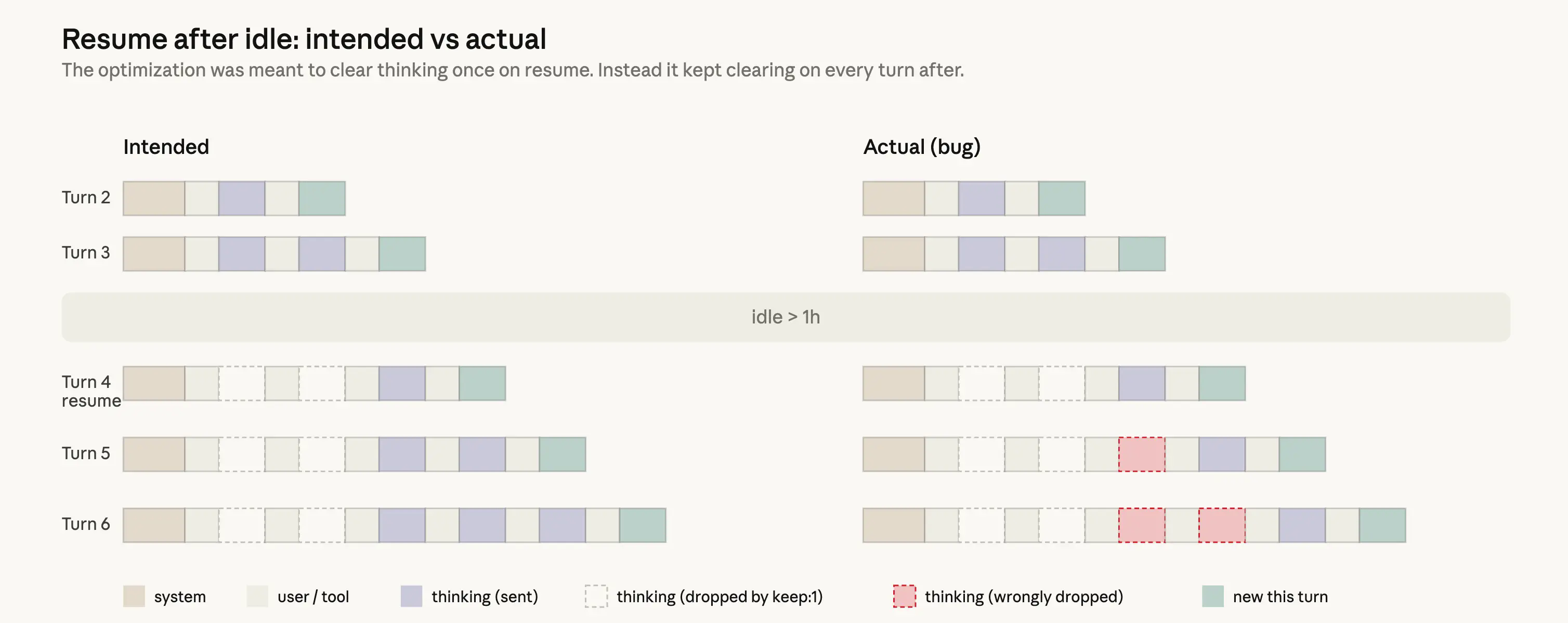
其次,一项针对空闲会话的缓存优化存在逻辑缺陷,错误地在后续每个回合清除了历史推理,导致模型表现出健忘和重复,并因持续缓存未命中而加速消耗用户的使用额度。
最后,为控制最新模型 Opus 4.7 输出过于冗长而引入的系统提示词长度限制,经后续广泛评估证实导致 Opus 4.6 和 4.7 质量下降 3%,该提示词已被移除。
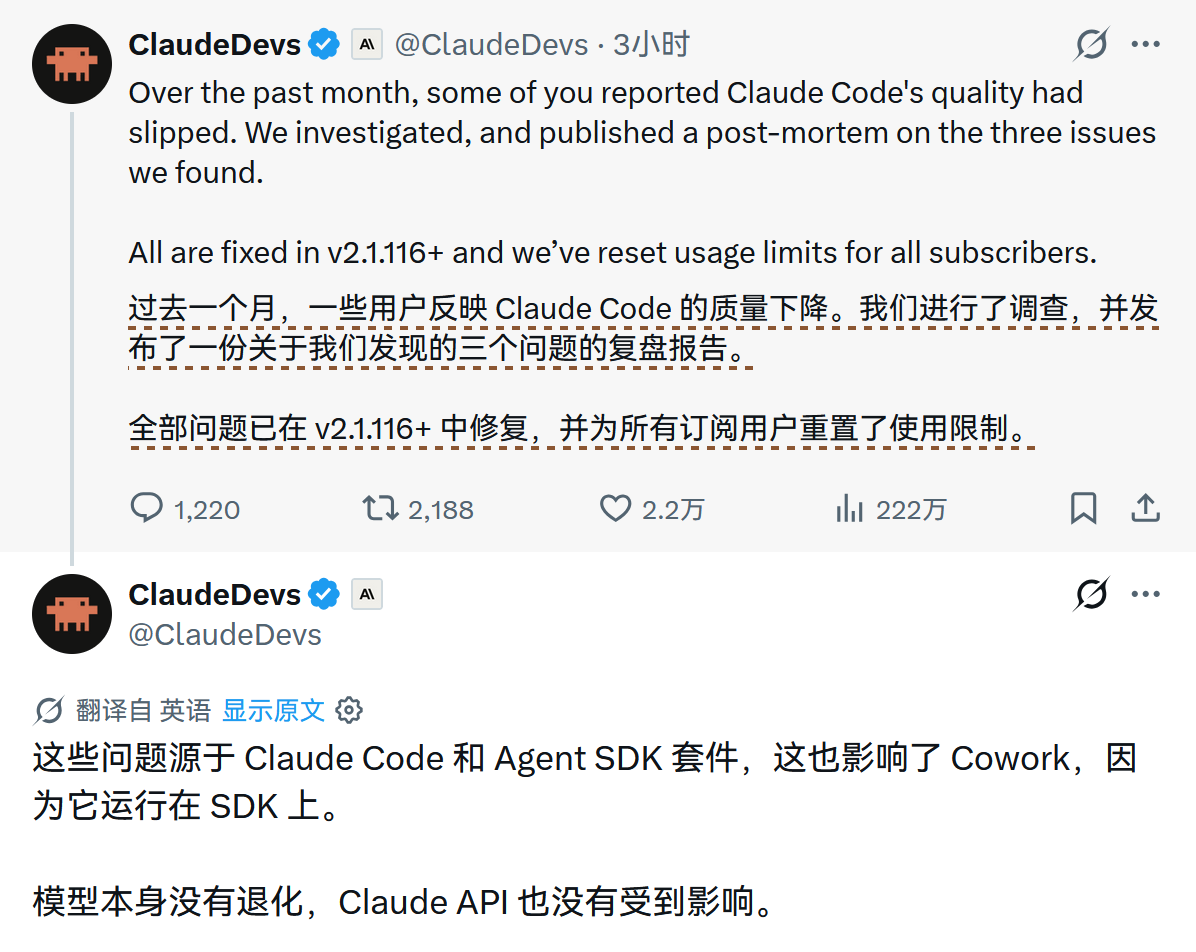
目前,上述所有问题均已在 v2.1.116 及以上版本中得到全面修复,Anthropic 已重置所有订阅者的使用限制以作补偿。
为防范类似情况,该公司承诺将扩大内部对公共构建版本的测试,强化系统提示词的审查与模型隔离,并已创建 @ClaudeDevs 社交账号及 GitHub 集中讨论区以深化与用户的沟通。

相关链接:
- https://www.anthropic.com/engineering/april-23-postmortem
- https://code.claude.com/docs/en/code-review
- https://x.com/ClaudeDevs/status/2047371123185287223
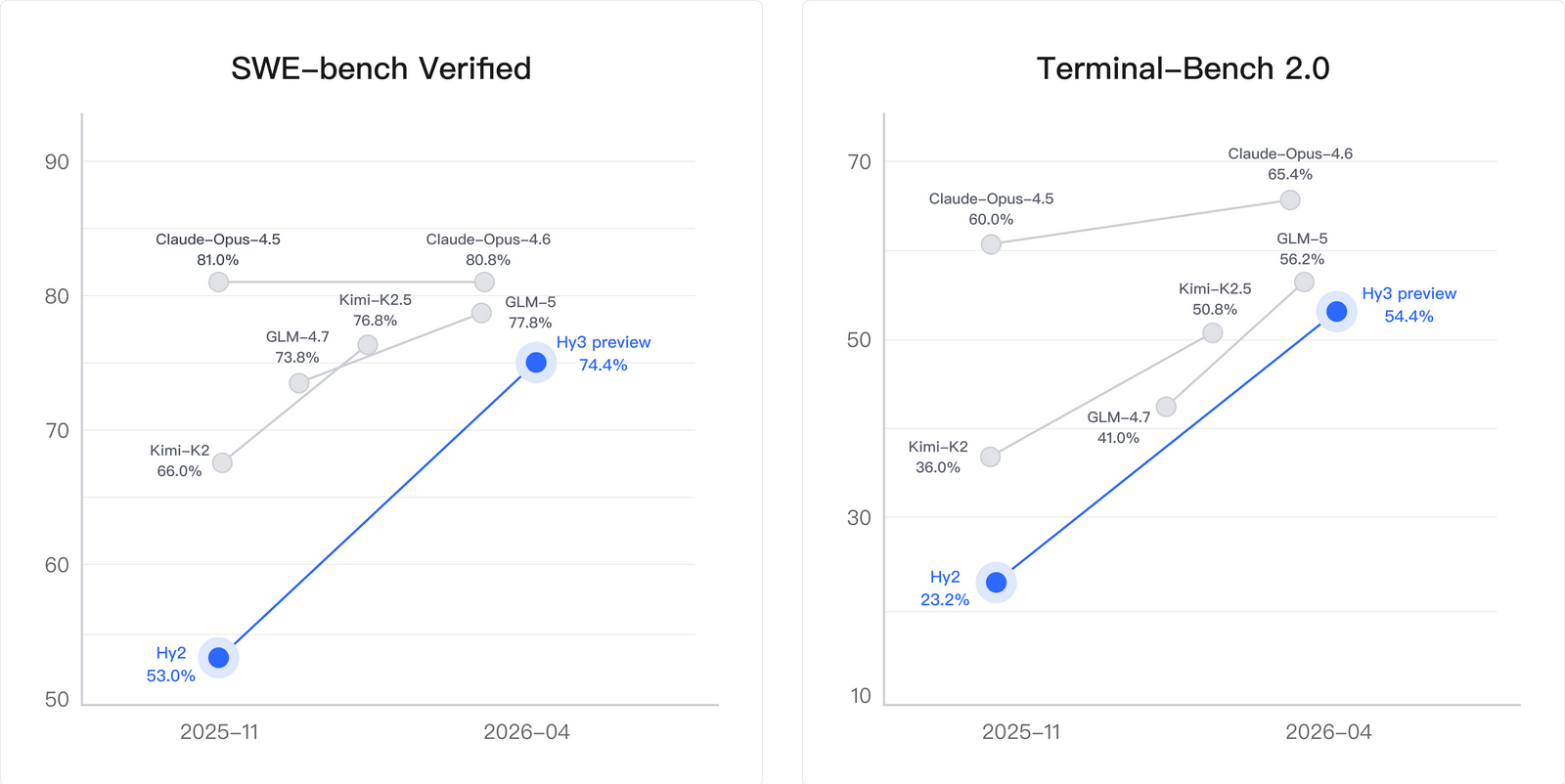
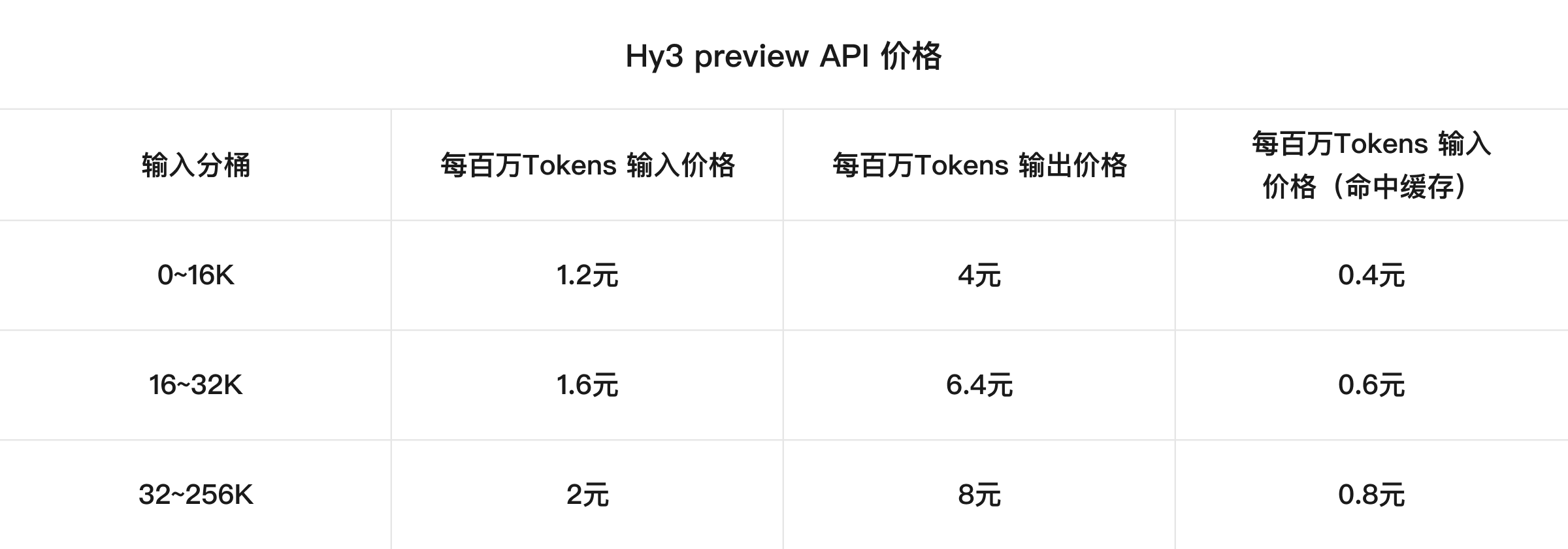
腾讯混元发布并开源 Hy3 preview 模型 #3
腾讯混元团队发布并开源了其新一代旗舰模型预览版
Hy3 preview。该模型采用
MoE架构,总参数量达 295B,激活参数量为 21B。这款模型主打高性价比与实用性,在复杂推理、代码和智能体任务上的能力实现了大幅提升。目前,该模型已上线 API 和官方 Token Plan,同时也全面接入了元宝、QQ 和微信等内部核心产品线。此外,该模型还在 OpenRouter 和 OpenCode 等平台提供限时免费调用。
腾讯混元团队近期正式发布并开源了 Hy3 preview 模型。该模型是 混元团队自 2月份 重建预训练和强化学习基础设施后推出的首款产品,定位为“混元大模型重建的第一步”。
Hy3 preview 采用了 MoE 架构,总参数量为 295B,激活参数量为 21B,并包含 3.8B 的 MTP 层参数,最大支持 256K 上下文长度。官方表示,其在复杂推理、指令遵循、上下文学习、代码及 Agent 任务上的能力实现了大幅提升,并主打全面实用性与高性价比。
目前,该模型的权重已在 Hugging Face、GitHub、ModelScope 和 GitCode 等平台开源。同时,该模型通过 腾讯云 提供 API 和 Token Plan 服务,并在 OpenRouter 和 OpenCode 等第三方平台开启限免。腾讯内部的元宝、QQ、微信等多个核心产品线也上线了该模型。


相关链接:
- https://hy.tencent.com/hy3-preview
- https://github.com/Tencent-Hunyuan/Hy3-preview
- https://huggingface.co/tencent/Hy3-preview
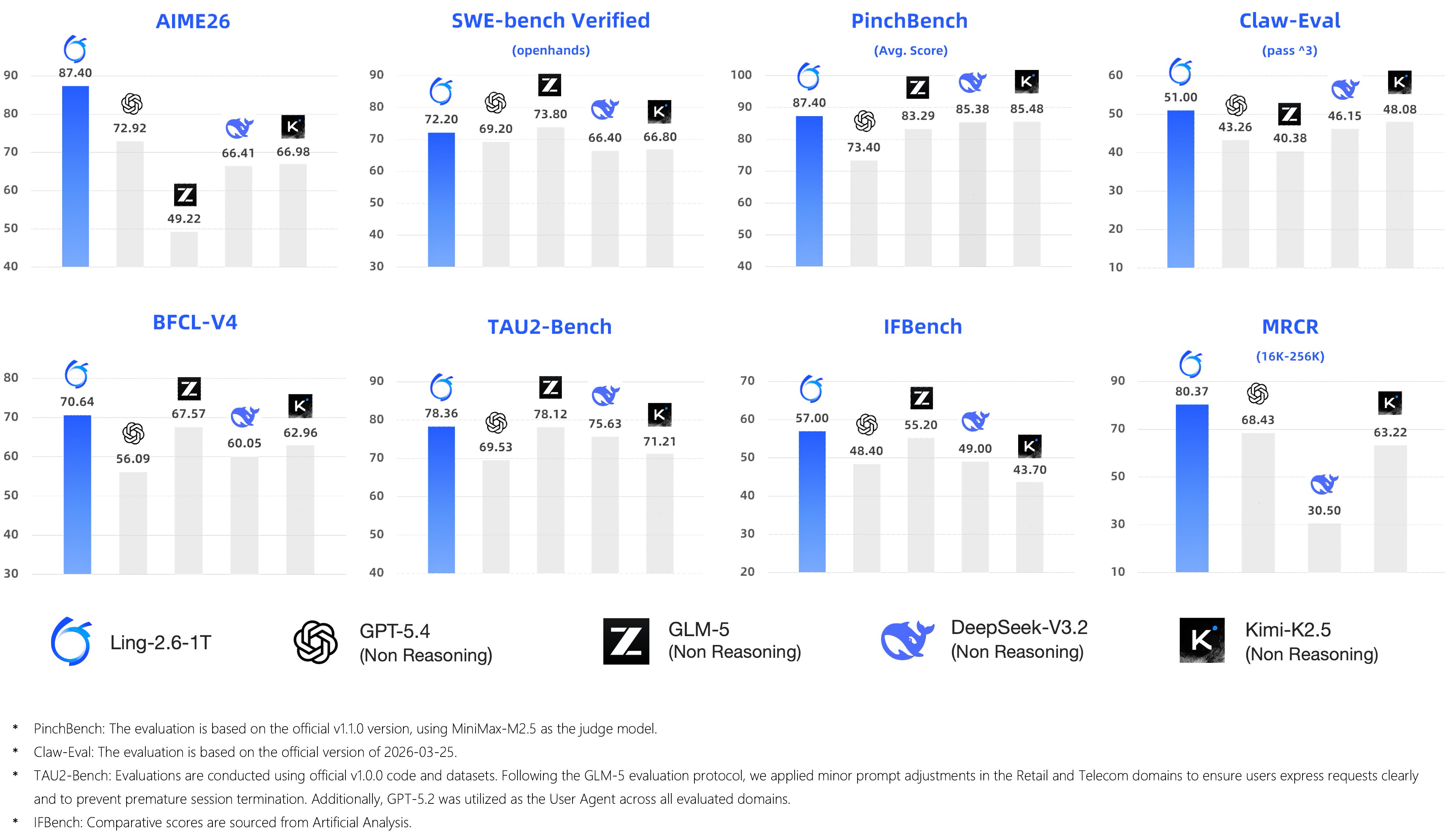
蚂蚁百灵发布 Ling-2.6-1T 模型,提供试用并计划开源 #4
蚂蚁集团 百灵团队 发布了
Ling-2.6-1T模型。该模型不支持思考模式,主打精确指令执行和超低 token 消耗。目前该模型已在 OpenRouter 和 Kilo 平台提供为期 一周 的免费 API 试用。官方 同时表示正准备开源该模型权重。
蚂蚁集团发布了 Ling-2.6-1T 万亿参数旗舰模型。该模型不支持思考模式,专为精确的指令执行任务设计,通过优先采用"Fast-Thinking"机制,实现了 SOTA 级别的智能表现与超低 token 开销。
官方称其性能媲美 GPT-5.4(非推理版),且在 AIME26 基准测试的非推理模型中处于领先地位。目前该模型已在 OpenRouter 和 Kilo 平台提供为期 一周 的免费 API 试用。官方同时宣布正准备开源该模型权重。

相关链接:
- https://x.com/AntLingAGI/status/2047374871467012393
- https://openrouter.ai/inclusionai/ling-2.6-1t:free
蚂蚁集团开源 LLaDA2.0-Uni 统一多模态模型 #5
蚂蚁集团 百灵团队发布了统一多模态模型
LLaDA2.0-Uni。该模型能够无缝完成视觉问答、图像生成与编辑等多种复杂任务。
目前,该模型已在相关平台开源。
蚂蚁集团 百灵团队发布了 LLaDA2.0 系列的首个统一多模态模型 LLaDA2.0-Uni。该模型基于 MoE 架构构建,总参数量达 16B(每个 token 激活约 1B 参数),能够在单一模型中无缝集成多模态理解与生成能力。
LLaDA2.0-Uni 支持高保真文本到图像生成(包含可选的思考/推理过程)、视觉问答与文档理解、单/多参考图指令编辑以及交错生成与推理。其底层采用统一的 dLLM-MoE 骨干网络与分块掩码 Token 预测范式,并配备 SigLIP-VQ 离散语义 Tokenizer 以及经过蒸馏的 8 步快速推理扩散解码器。
为了提升推理效率,该模型引入了 SPRINT 加速技术,结合 KV cache 复用与自适应去掩码策略优化计算。该项目已在 Hugging Face 上开源并提供技术报告,基于 Apache 2.0 许可证发布。

相关链接:
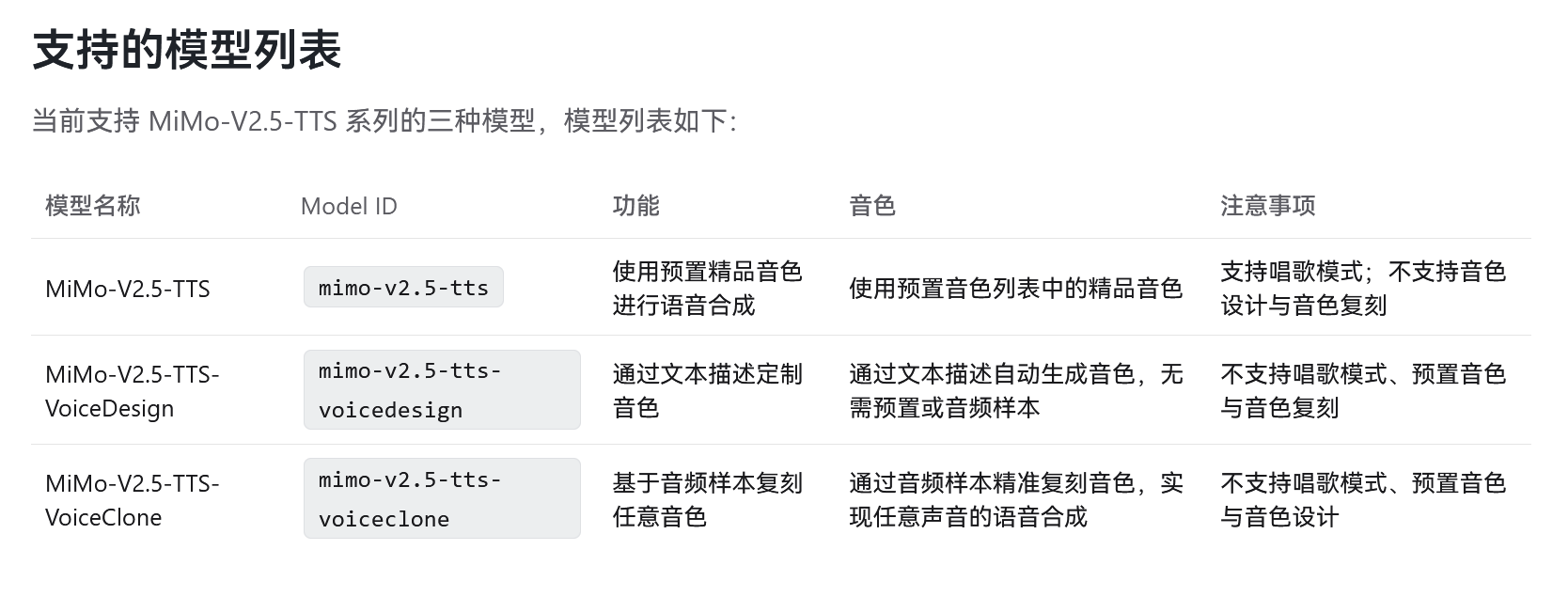
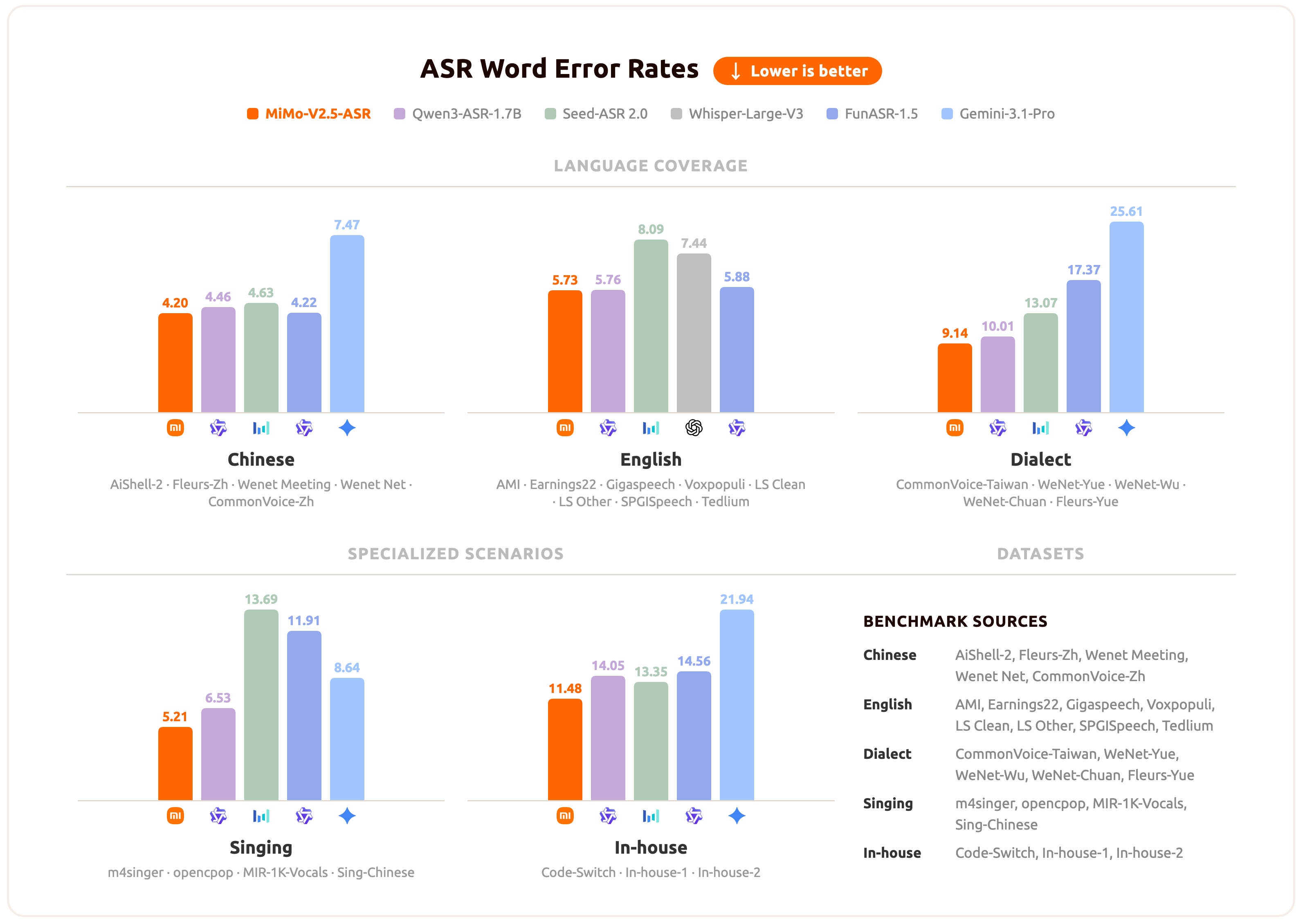
小米 MiMo 发布语音模型系列,8B 参数 ASR 开源 #6
小米 MiMo 团队正式发布了
MiMo-V2.5-TTS Series与MiMo-V2.5-ASR模型。其中,
MiMo-V2.5-TTS Series包含基础 TTS、VoiceDesign 和 VoiceClone 三款模型,并限时免费提供 API。另一款
MiMo-V2.5-ASR是一款拥有 8B 参数的端到端自动语音识别模型,目前已在相关平台开源。
小米 MiMo 团队近日正式发布面向 Agent 时代的全链路语音模型系列——MiMo-V2.5-TTS Series 与 MiMo-V2.5-ASR,实现语音输入与输出的语言自由调度。
其中,MiMo-V2.5-ASR 是一款拥有 8B 参数的端到端自动语音识别模型,目前已在 Hugging Face 和 GitHub 上正式开源。
该模型通过大规模中间训练、高质量监督微调及新型强化学习算法,在中英双语、中文方言、Code-Switch、强噪音、多说话人及高知识密度等复杂场景下均达到官方宣称的业界领先水平。
同步推出的 MiMo-V2.5-TTS Series 包含基础 TTS、VoiceDesign(音色设计)和 VoiceClone(音色克隆)三款模型,现已在 小米 MiMo 开放平台上线并限时免费开放 API。
其具备精细的风格指令遵循、行内音频标签控制与无需提示词的丰富文本理解能力。
相关链接:
- https://platform.xiaomimimo.com/docs/usage-guide/speech-synthesis-v2.5
- https://github.com/XiaomiMiMo/MiMo-V2.5-ASR
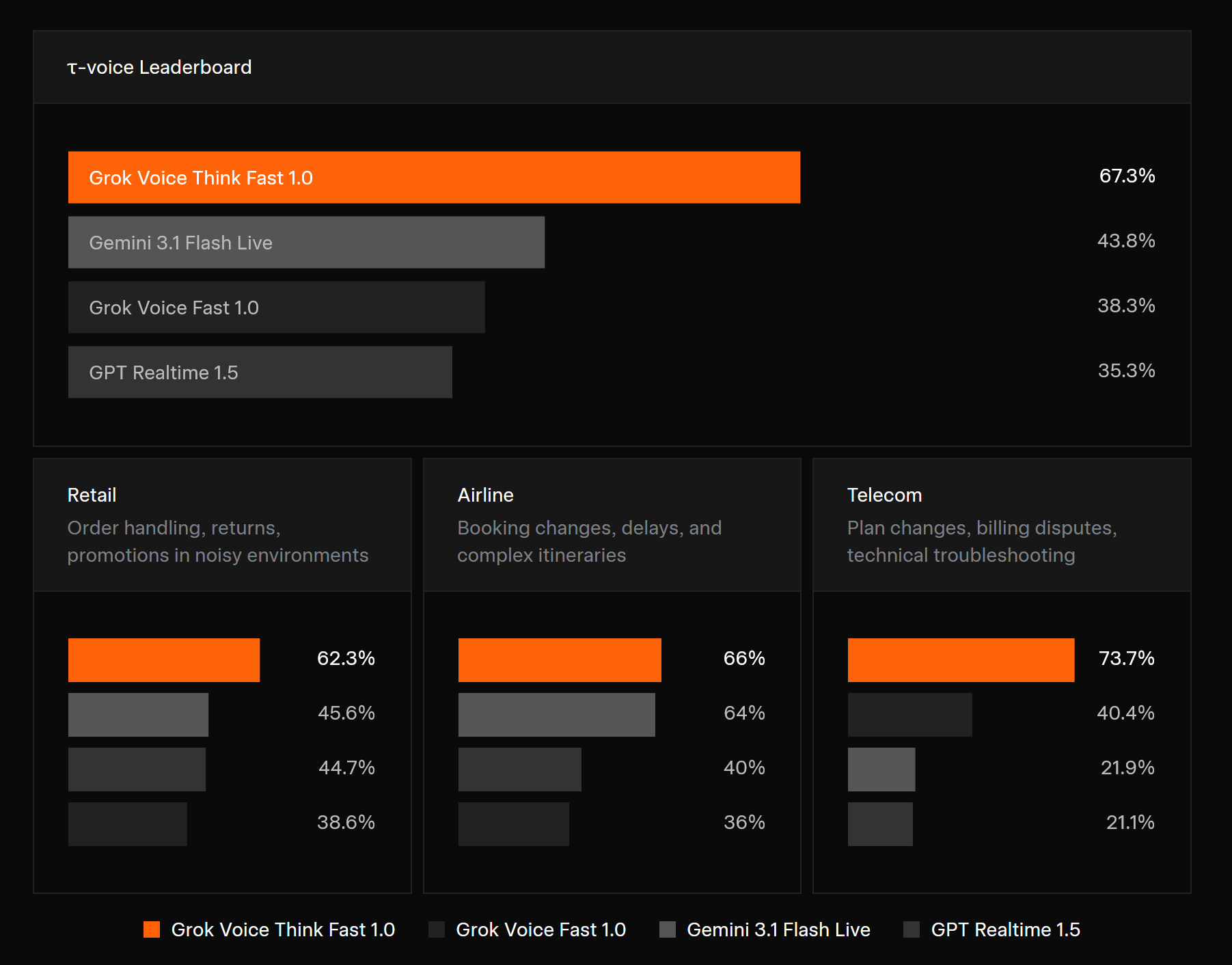
xAI 发布语音模型 grok-voice-think-fast-1.0 #7
xAI 发布了旗舰语音模型
grok-voice-think-fast-1.0并开放 API。该模型在语音智能评测中排名第一。
它支持 25 种以上 语言,能后台实时推理且不增加延迟。
近日,xAI 官方宣布推出全新的旗舰语音模型 grok-voice-think-fast-1.0,并已通过 API 正式开放。
该模型专为复杂、模糊和多步骤的工作流设计,能够在不影响响应延迟的情况下于后台进行实时推理,具备精确的数据收集与高并发工具调用能力。
官方博客显示,该模型在评估全双工语音 Agent 的 τ-voice Bench 排行榜上登顶,原生支持 25 种以上 的语言,能够从容应对噪音、口音及频繁打断等真实复杂环境。
相关链接:
字节跳动发布 Seed3D 2.0,几何纹理生成达 SOTA 表现 #8
字节跳动 Seed 团队发布了新一代3D生成大模型
Seed3D 2.0,该模型通过架构升级大幅提升了几何精度与材质真实感,并拓展了部件级生成与场景组合等实际应用能力。目前,该模型API已上线火山引擎。
字节跳动 Seed 团队正式发布了新一代 3D 生成大模型 Seed3D 2.0。该模型针对几何精度与材质质量进行了架构升级,官方称其在几何及纹理材质生成两项核心指标上均达到 SOTA 表现,旨在推动 3D 生成迈向“生产可用”。
Seed3D 2.0 引入了 Coarse-to-Fine 两阶段 DiT 生成策略以优化几何细节,并采用统一的 PBR 生成模型与 MoE 架构提升纹理真实感与边界精度。在性能评估方面,官方数据显示,在盲评中,该模型在几何生成上展现出显著优势,且在纹理 3D 内容生成上的偏好率达到 69% 以上。
此外,该模型还拓展了部件级分割与补全、铰接资产生成以及基于多模态输入的场景组合等下游任务,以增强实际部署能力。目前,Seed3D 2.0 的技术报告已公开,其 API 也已上线 火山引擎。用户可通过 火山方舟 体验中心选择对应的视觉模型进行体验。

相关链接:
- https://seed.bytedance.com/zh/blog/seed3d-2-0-released-higher-precision-and-greater-usability
- https://seed.bytedance.com/zh/seed3d_2_0
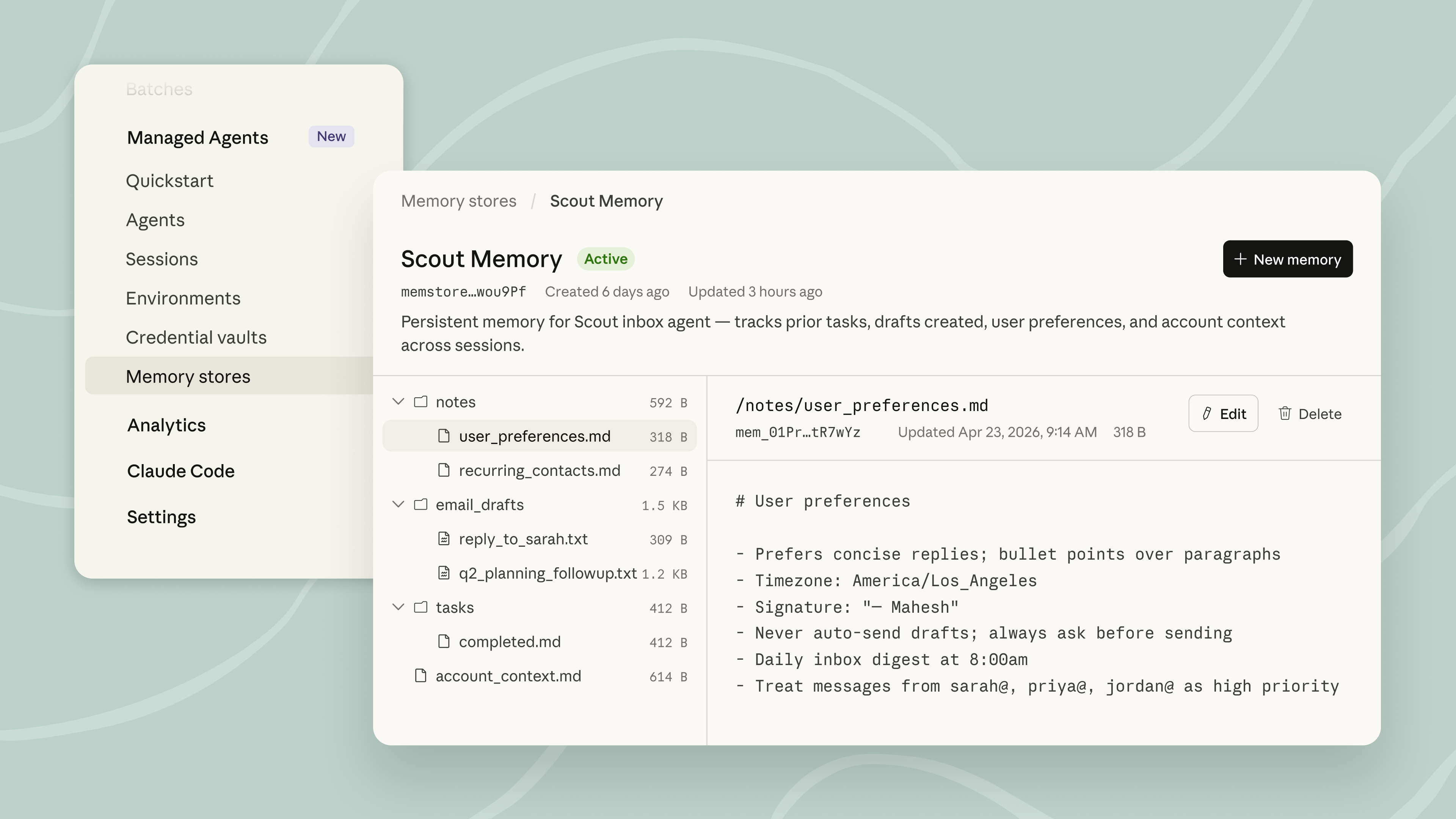
Claude 宣布 Managed Agents 内置记忆功能开启公开测试 #9
Claude 官方宣布,Claude Managed Agents 的内置记忆功能现已进入公开测试阶段。
这项功能让智能体能够从每次会话中不断学习并保存记忆。
开发人员可以通过
API对其进行完全控制。
Claude 官方近日宣布,Claude Managed Agents 的内置记忆功能现已进入公开测试阶段。
该功能允许 Agent 从每次会话中学习,通过一个旨在平衡性能与灵活性的智能优化记忆层来实现。
在技术实现上,记忆被存储为文件并直接挂载到文件系统上,这使得 Claude 能够利用其现有的 bash 和代码执行能力来处理任务。
开发人员可以导出这些记忆,通过 API 对其进行管理,并保持对保留内容的完全控制。
开发人员现在可以通过 Claude Console 或新的 CLI 部署首个具备记忆功能的 Agent,并有官方文档可供参考。
相关链接:
- https://claude.com/blog/claude-managed-agents-memory
- https://platform.claude.com/docs/en/managed-agents/memory
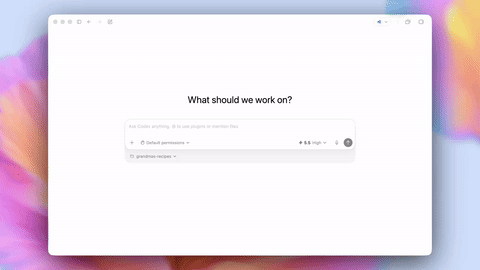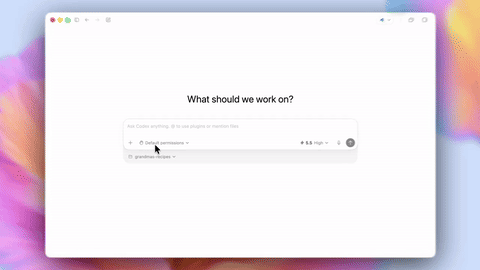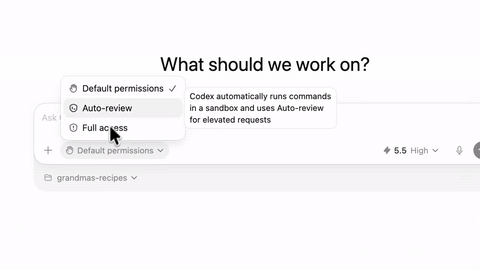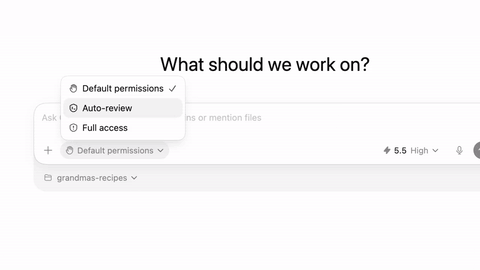
Codex 上线 GPT-5.5,优化浏览器控制并新增 Auto-review 模式 #10
OpenAI宣布 Codex 应用已全面接入
GPT-5.5,并推出多项重大升级。新版本大幅增强了浏览器和电脑自动操作能力,改进了 Office 和 Google Drive 文档处理,还加入了 Auto-review 模式和系统级听写等功能。
OpenAI 官方宣布,Codex 迎来重大更新,全面接入 GPT-5.5 模型。
根据官方提供的数据,该模型在 Codex 中支持 400K 上下文窗口。此次更新向 Plus、Pro、Business、Enterprise、Edu 及 Go 计划的用户开放。其 Fast 模式生成 Token 的速度提升 1.5 倍,但相应成本会增加 2.5 倍。
此次更新标志着 Codex 从代码工具向全方位计算机操作 Agent 转变,重点强化了浏览器交互、文档处理与长任务自动化能力。
在浏览器端,Codex 现已支持直接操作 Web 应用、点击页面及基于截图的视觉自我迭代。
在文档处理方面,其能直接在 Microsoft Office 和 Google Drive 中生成高质量的电子表格与幻灯片。
此外,该产品新增了 Auto-review 模式,通过独立的审查 Agent 在高风险操作前进行上下文检查以减少人工干预。
相关链接:
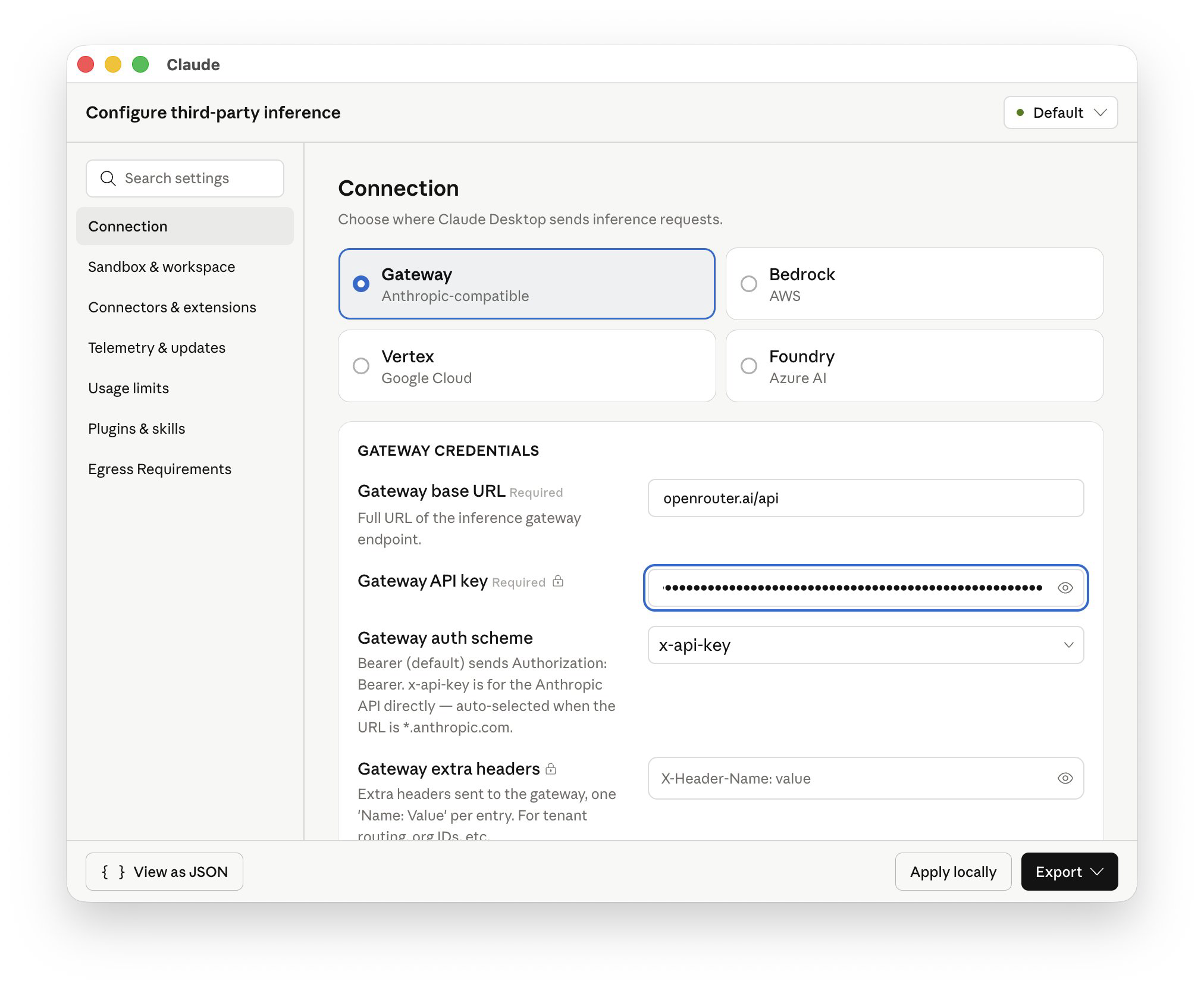
Claude 桌面端被发现支持配置第三方大语言模型接口 #11
Anthropic 旗下的 Claude Desktop 应用已被证实能够接入并使用第三方大语言模型。
用户只需在应用内开启开发者模式,即可手动配置第三方推理接口。
近日,Claude Desktop 被发现支持配置并使用第三方大语言模型。据多位社区用户测试反馈,该功能无需登录账户即可使用。
用户只需在应用顶部菜单栏依次点击 Help、Troubleshooting 并启用 Enable developer mode,随后便可通过新增的 Developer 菜单进入 Configure Third-Party Inference 界面配置第三方接口。
根据官方帮助中心文档显示,该功能主要面向 IT 管理员。官方称之为"Claude Cowork with third-party platforms",旨在帮助企业将 Claude Desktop 接入 Amazon Bedrock、Google Cloud Vertex AI、Azure AI Foundry 或任何暴露 /v1/messages 接口的 LLM 网关。
相关链接:
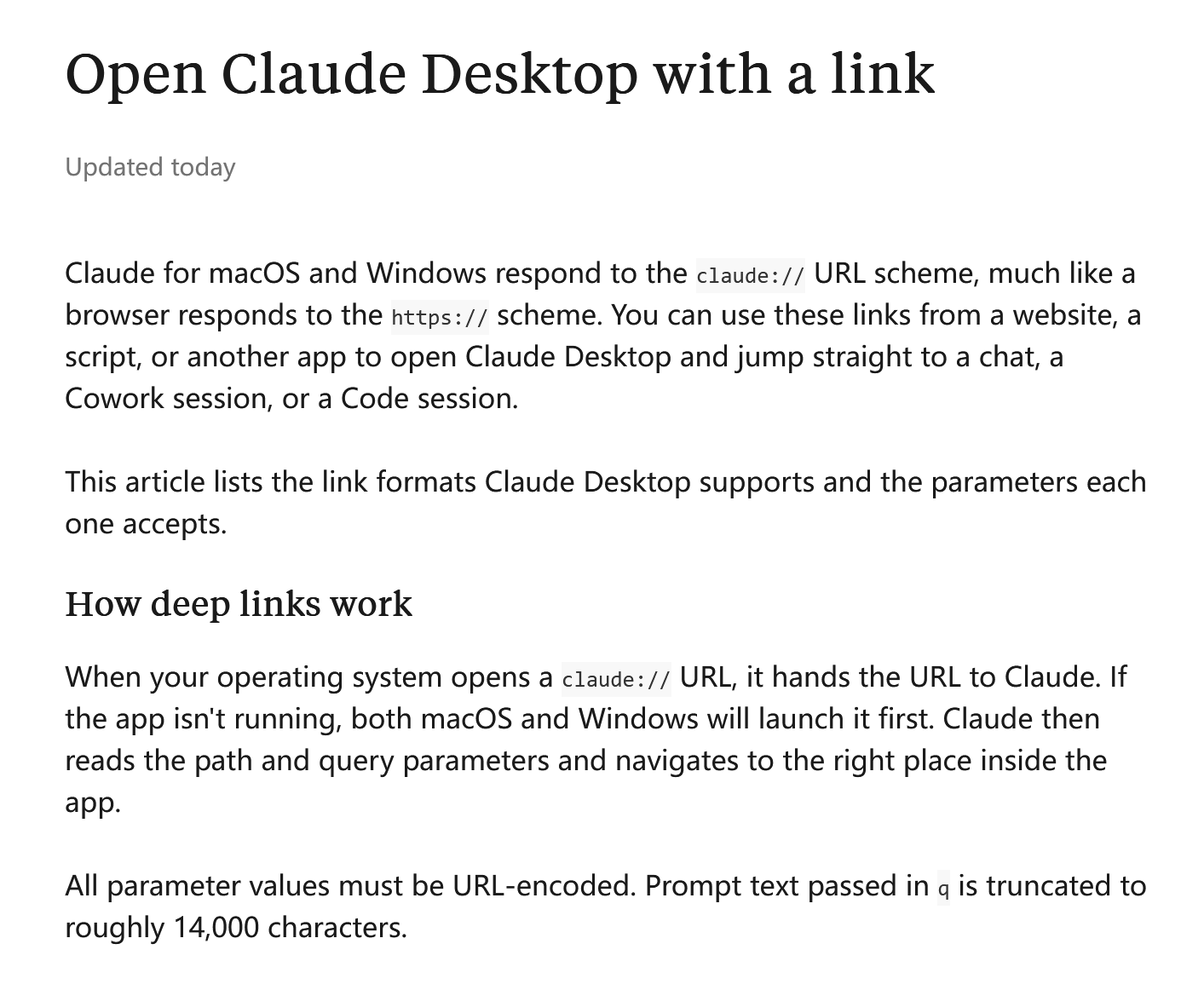
Claude 桌面端支持 URL 协议唤起特定会话及文件 #12
Claude Desktop 的 Mac 和 Windows 版本现已正式支持
claude://链接唤起功能。用户通过点击特定链接就能直接启动客户端,快速跳转到指定的对话或编程会话。
并且该功能还支持预填充提示词以及附加文件路径。
Claude Desktop 的 macOS 与 Windows 版本最新支持了 claude:// URL scheme 功能。
根据 Claude Help Center 发布的文档,用户可以通过网站、脚本或其他应用内的链接直接唤起 Claude Desktop。若应用未运行,操作系统会先行启动它,并直接跳转至特定的 Chat、Cowork 或 Code 会话。
该功能支持通过参数预填充提示词、附加指定文件或文件夹路径,且传入的提示词字符数上限约为 14,000 个。
这项新特性可用于工作流组合或为其他工具添加"Open in Claude"按钮,但该功能必须配合桌面端应用使用。
相关链接:
- https://support.claude.com/en/articles/14729294-open-claude-desktop-with-a-link
- https://x.com/felixrieseberg/status/2047367515500659128
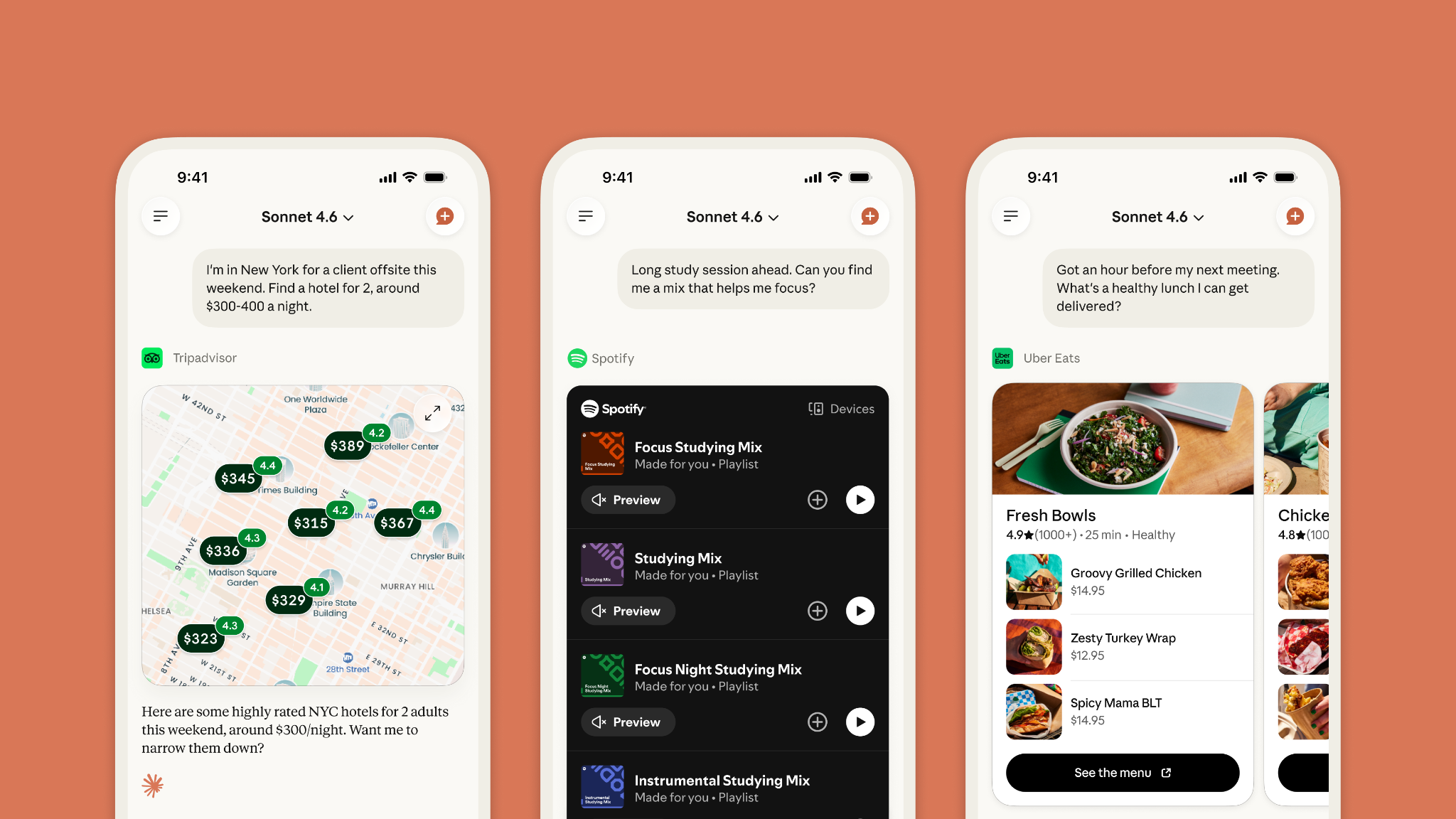
Claude 扩展 Connectors,新增 15 款日常生活应用 #13
Claude 宣布扩展其
Connectors功能,新增支持 15 款涵盖衣食住行的日常生活应用,并能在对话中根据上下文动态推荐相关应用。目前该功能已面向所有用户开放。
Claude 官方宣布扩展其 Connectors 功能,新增支持 AllTrails、Audible、Booking.com、Instacart、Intuit Credit Karma、Intuit TurboTax、Resy、Spotify、StubHub、Taskrabbit、Thumbtack、TripAdvisor、Uber、Uber Eats 和 Viator 等 15 款日常生活应用。
这一举措将原本涵盖 200 多个连接器的协同工作能力延伸至日常场景。
该功能现已在对话中支持动态建议,可根据用户偏好和上下文自动推荐合适的已连接应用,并在有多个应用适用时供用户选择。
官方强调该产品无广告且无赞助内容,承诺应用数据不会用于模型训练,且在执行预订或购买等操作前会要求用户确认。
目前该功能已面向所有订阅计划开放。
相关链接:
OpenAI 发布 ChatGPT for Clinicians ,推出 HealthBench 评测基准 #14
OpenAI 推出了面向美国境内医疗从业者免费开放的
ChatGPT for Clinicians,同步推出全新评测基准HealthBench Professional。
OpenAI 近期宣布推出专为临床工作设计的免费版本 ChatGPT for Clinicians,以及全新的开放评测基准 HealthBench Professional。该产品目前主要面向美国境内经过验证的医生、NP、PA 和药剂师免费开放,旨在支持临床护理、文档撰写和医学研究等任务。
在功能层面,该产品不仅提供针对复杂临床问题的前沿 AI 模型访问,还具备可复用临床工作流技能。它支持基于数百万份同行评审医学文献的实时可信临床搜索,以及跨医学期刊的深度研究支持。此外,用户在研究临床问题时可自动获得 CME 学分。该平台也提供基于 BAA 的可选 HIPAA 合规支持,并承诺不使用用户对话训练模型。
根据官方博客提供的数据,在 HealthBench Professional 测试中,该工作区内的 GPT-5.4 模型表现超越了基础版 GPT-5.4、其他所有参与对比的模型,甚至击败了拥有无限时间和网络访问权限的人类专科医生。
OpenAI 计划在未来几个月内与 Better Evidence Network 合作,将访问权限扩展至美国以外的临床医生,并同步发布了关于在医疗保健领域负责任地整合 AI 的 Health Blueprint。

相关链接:
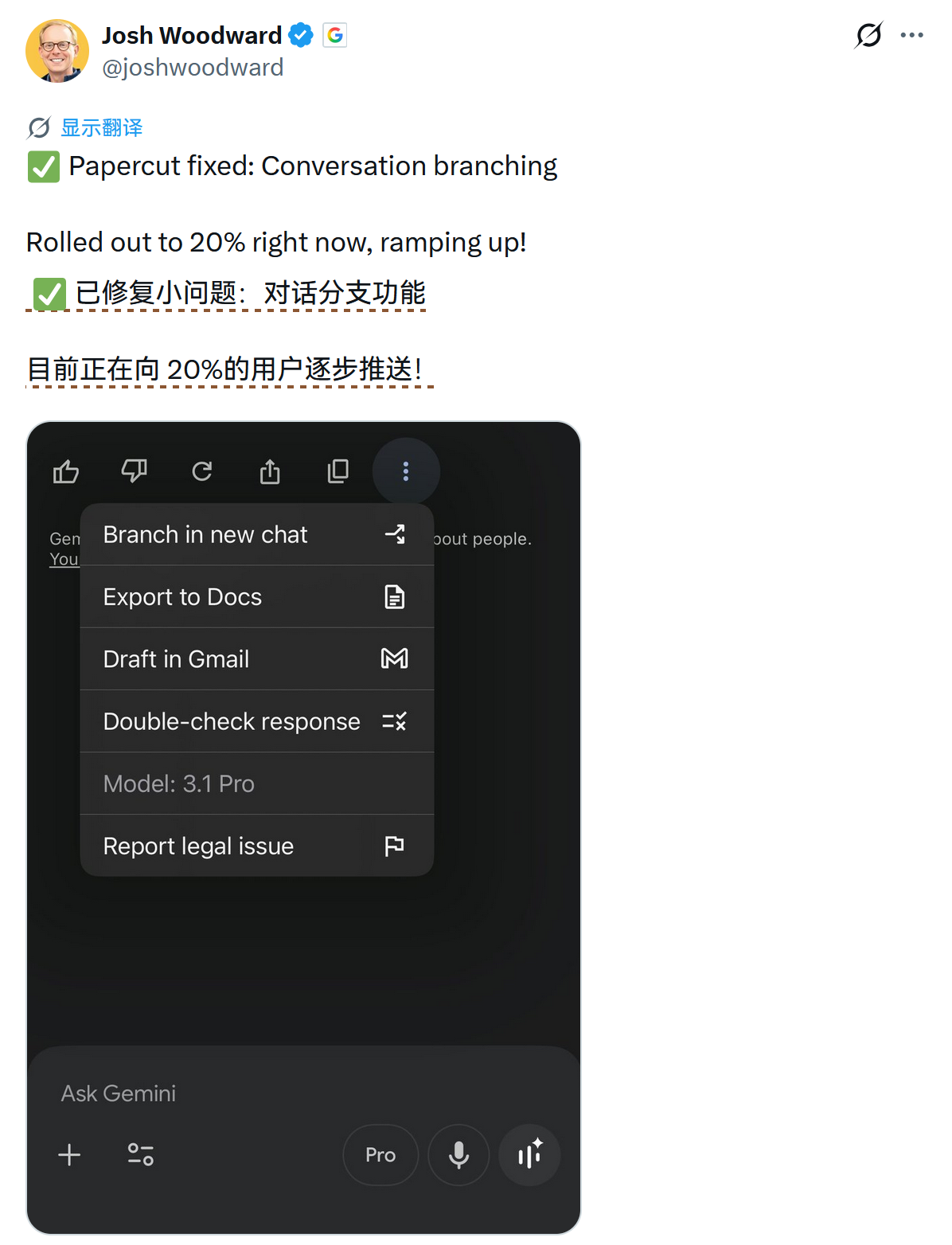
Gemini 推出对话分支功能,逐步推送中 #15
Gemini 工作人员宣布 Gemini 推出对话分支功能,目前正逐步推送该功能。
近日,Gemini 工作人员 Josh Woodward 在社交平台宣布团队完成了一项功能更新。
据其公开声明,Gemini 正式推出了 Conversation branching(对话分支)功能。
目前该功能的推送规模正在持续提升,逐步向更广泛受众扩大。
相关链接:
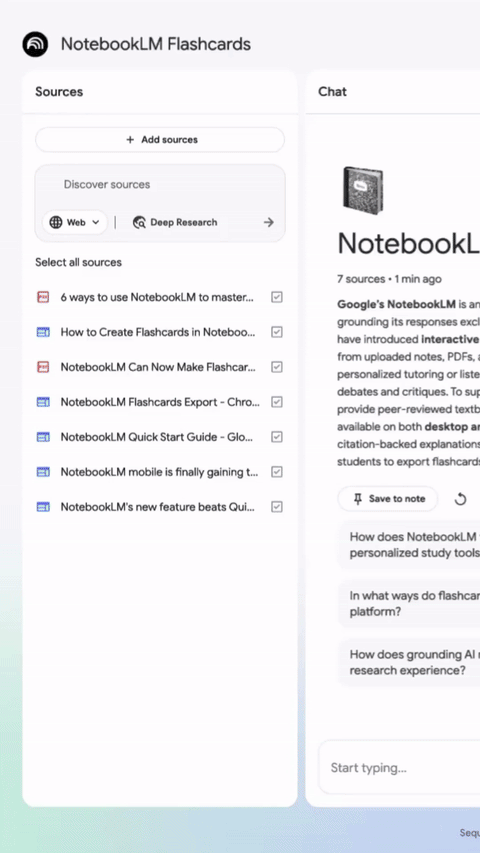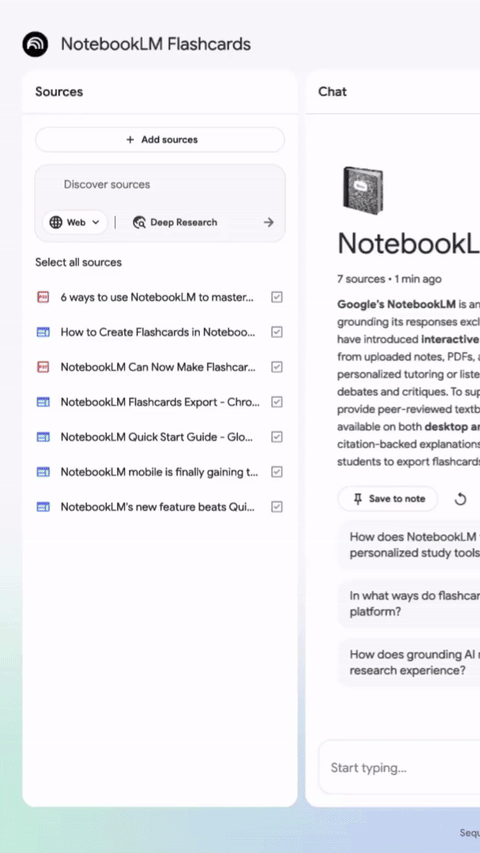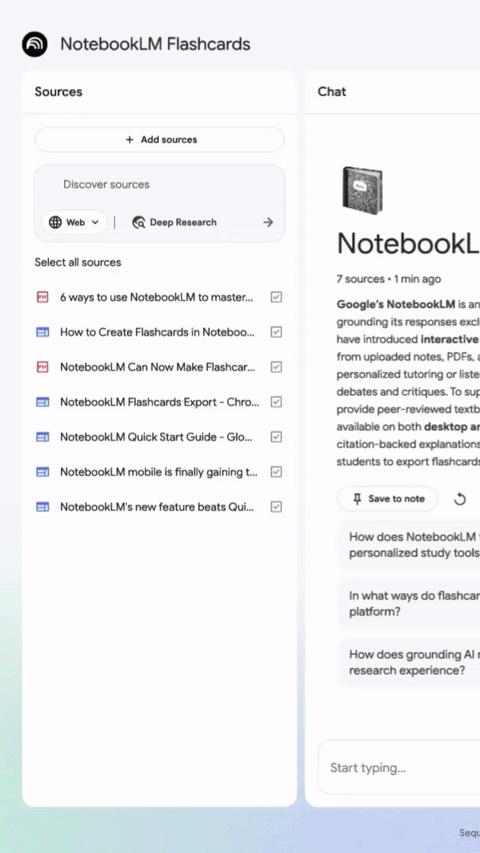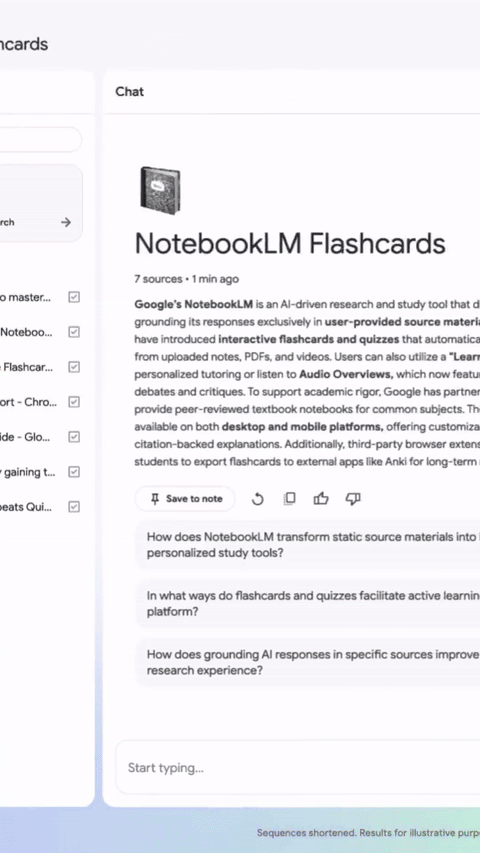
NotebookLM 优化多人分享流程,新增支持断点续学 #16
NotebookLM 发布更新,现在用户能通过批量粘贴邮箱一键分享笔记本。
Quizzes与Flashcards功能也新增了保存进度、断点续学以及学习状态追踪等实用体验。
近日,NotebookLM 官方宣布对其产品的协作分享与学习功能进行了两项重要更新。
在协作方面,该产品优化了多用户分享流程。用户现在可通过直接复制粘贴邮箱地址列表的方式向多人同时分享笔记本,免去了过去逐一添加电子邮件地址的繁琐步骤。
同时,根据 NotebookLM 团队的说明,该产品的 Quizzes 与 Flashcards 功能基于用户反馈迎来了重大升级。
升级后的功能允许用户和学生保存学习进度并支持断点续学,提供了对卡片的随机排序与删除选项,并加入了追踪机制以明确区分已掌握内容与待复习内容。
相关链接:
OpenClaw 发布 2026.4.22 版,扩展多模型与语音支持 #17
OpenClaw 正式发布了 2026.4.22 版本更新,重点扩展了多模型与语音处理能力,新增了多个提供商的集成。
同时,新版本引入
TUI模式和自动安装缺失plugin功能。此外,本次更新还包含诊断导出等实用功能。
OpenClaw 官方正式发布了 2026.4.22 版本更新,此次升级重点扩展了多模型支持、语音处理能力与本地化运行体验。
在提供商集成方面,该版本新增了 Tencent Cloud bundled plugin 及其 TokenHub onboarding 流程与 hy3-preview 模型。同时为 xAI 引入了包含 grok-imagine-image 在内的图像生成、文本转语音及语音转文本支持。此外,还将 Deepgram、ElevenLabs 和 Mistral 纳入 Voice Call 实时流式转录支持范围。
在交互与控制方面,OpenClaw 新增了无需重启 Gateway 即可在聊天中注册模型的 /models add 命令。并引入了无需 Gateway 即可运行终端聊天的本地 TUI 嵌入模式。
此外,此次更新将 GPT-5 的提示词叠加层移至共享 provider 运行时,使其行为调优能够跨越 OpenAI、OpenRouter 等多种提供商生效。gpt-image-2 的 OAuth 支持即将推出。
针对系统稳定性与开发者体验,官方加入了自动安装缺失 plugin 和诊断导出功能,并对涉及多渠道的路由、会话及权限配置进行了全面修复与优化。

相关链接:
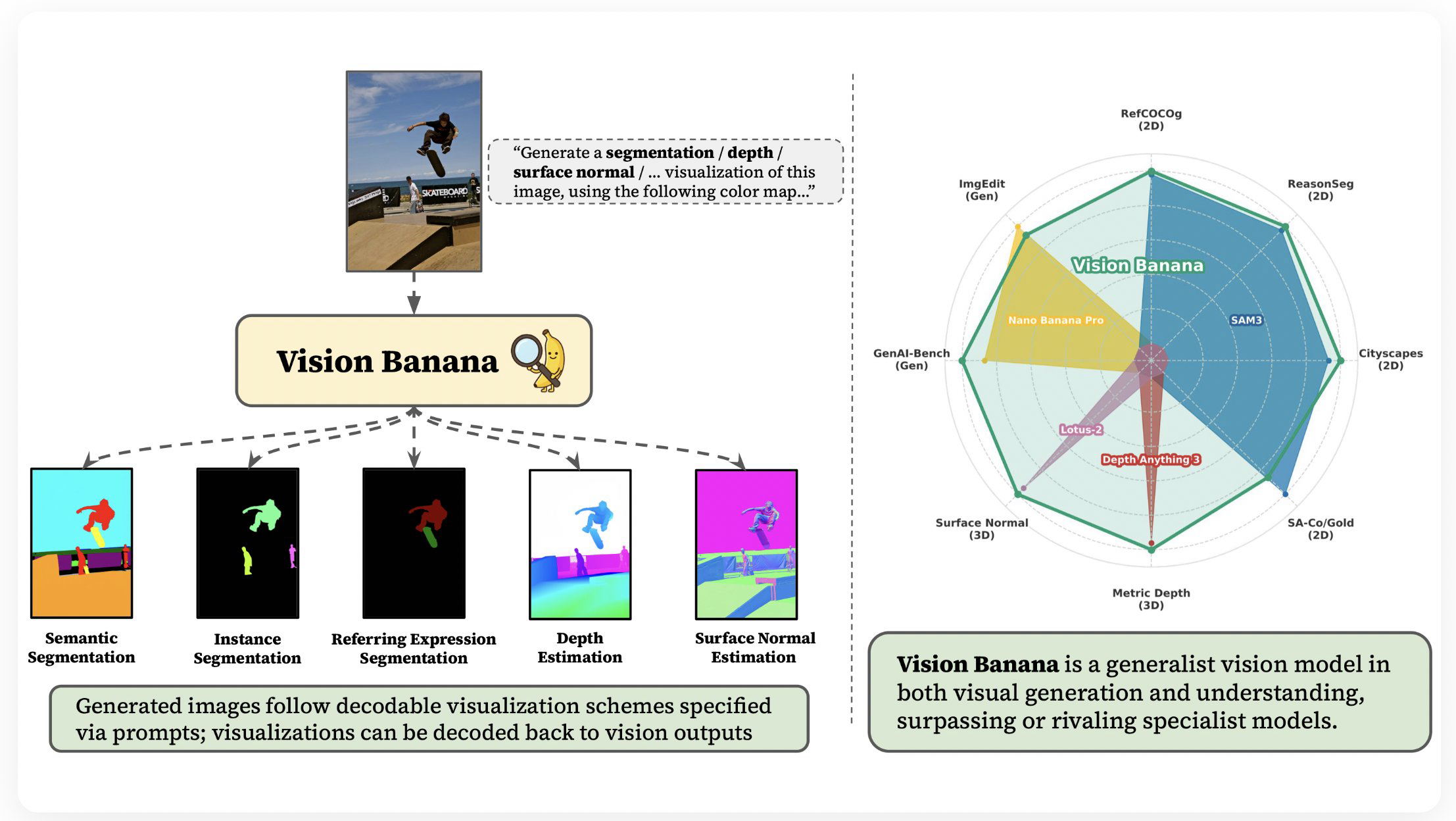
Google DeepMind 提出 Vision Banana 模型,视觉任务达最优水平 #18
Google DeepMind团队发表论文,提出了基于
Nano Banana Pro的通用视觉模型Vision Banana。该模型将各类视觉感知任务统一转化为图像生成问题。
在多项2D和3D视觉任务中,它达到了当前最优水平。其表现媲美甚至超越了多款专用领域模型。
Google DeepMind研究团队近日发布论文《Image Generators are Generalist Vision Learners》,提出通用视觉模型 Vision Banana。
该模型基于图像生成模型 Nano Banana Pro,经轻量级指令微调训练而成,其混合使用了基础模型的原始训练数据与少量视觉任务数据。通过将视觉任务的输出空间参数化为RGB图像,该技术将各类感知任务统一重构为图像生成问题。
Vision Banana在零样本迁移设置下,于语义分割、实例分割、指代表达分割、单目度量深度估计及表面法线估计等2D与3D视觉任务中达到当前最优水平,可媲美或超越 Segment Anything Model 3、Depth Anything系列等专用领域模型,且在训练与推理中均无需相机内参。
研究显示,该微调过程未损害基础模型的图像生成能力。团队认为,图像生成预训练有望如同大语言模型预训练一般,成为构建基础视觉模型的核心范式。
相关链接:
Google DeepMind 提出 Decoupled DiLoCo 架构,支持低带宽跨区大模型训练 #19
Google DeepMind 团队发布了一项名为
Decoupled DiLoCo的新型分布式架构,它能通过异步计算在混合使用不同型号芯片和低带宽网络的情况下让全球分布的数据中心协同训练大模型。
近日,Google DeepMind 团队发布了一项名为 Decoupled DiLoCo 的新型分布式架构,旨在通过解耦的“计算孤岛”和异步数据流,在全球分布的数据中心之间实现更具弹性和灵活性的 LLM 训练。
官方公告显示,该架构不仅能够隔离局部硬件中断并实现自我修复,还显著降低了对网络带宽的需求。
在实际测试中,研究人员利用 2-5 Gbps 的广域网成功在美国四个地区完成了 120 亿 参数模型的训练,其训练速度比传统同步方法快 20 倍以上。
此外,该系统支持在同一训练任务中混合使用如 TPU v6e 和 TPU v5p 等不同世代的硬件,并已通过 Gemma 4 模型验证了其能达到与传统方法相同的 ML 性能基准。

相关链接:
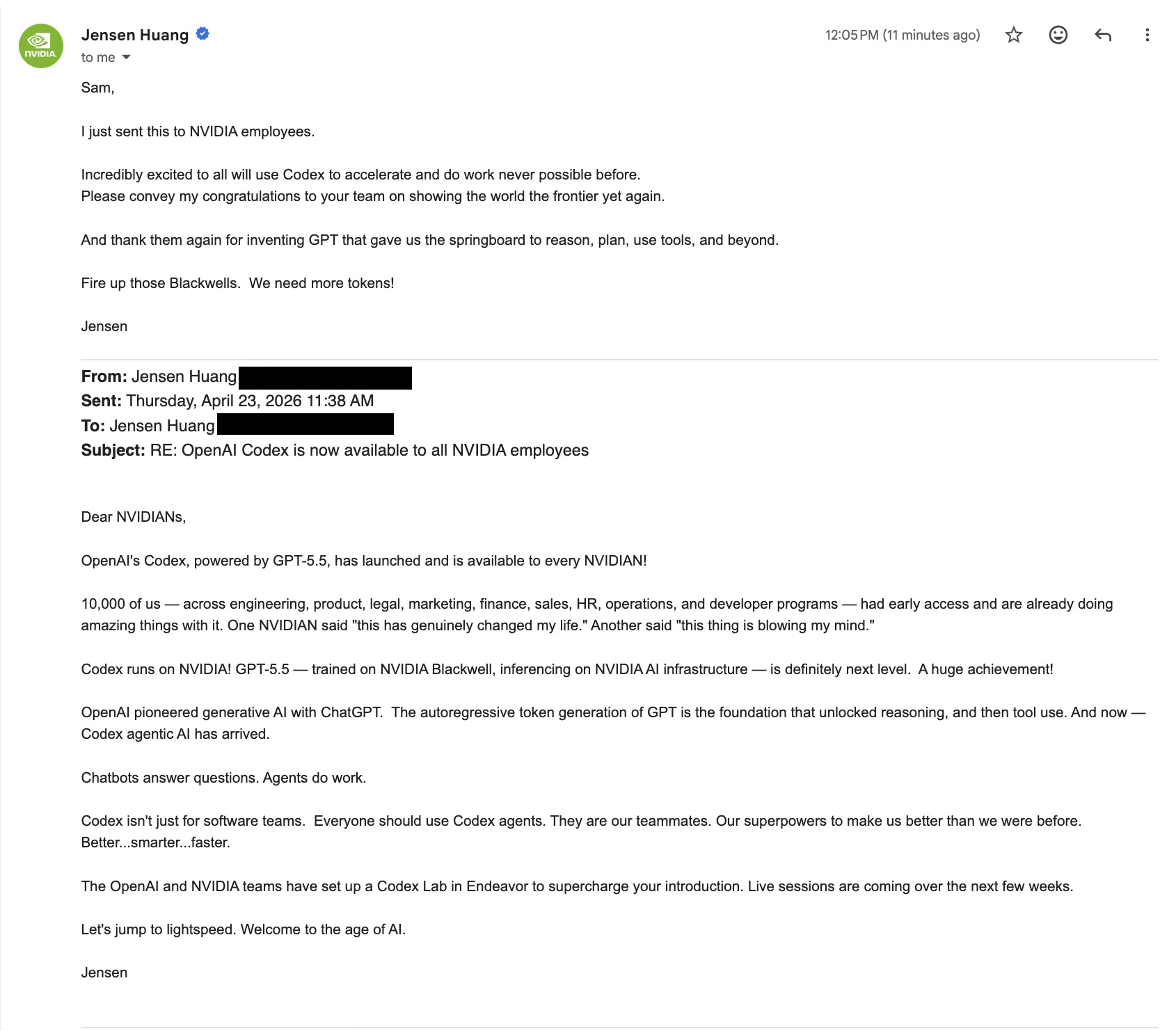
OpenAI 联合 NVIDIA 部署 Codex,万名员工接入 GPT-5.5 #20
OpenAI CEO Sam Altman 称,已将由
GPT-5.5驱动的Codex成功部署至NVIDIA全公司。目前NVIDIA九大业务部门的超一万名员工正在使用。Sam Altman也借此邀请其他企业联系OpenAI进行类似部署。
OpenAI首席执行官 Sam Altman宣布与 NVIDIA合作开展了一项全新的企业级部署尝试,已将 Codex成功推广至后者整个公司。
根据 OpenAI官方新闻账号的公告,NVIDIA目前已有超过 10,000名跨越工程、产品、法律、营销、财务、销售、人力资源、运营以及开发者项目等九大业务部门的员工正在使用由 GPT-5.5驱动的 Codex。
NVIDIA方面称该工具达到了“令人震惊”和“改变生活”的应用效果。
Sam Altman表示这项部署测试取得了出色的成果,并公开邀请其他有兴趣的企业联系 OpenAI进行类似的全公司级部署。

相关链接:
- https://x.com/sama/status/2047395562501411058
- https://x.com/OpenAINewsroom/status/2047430629550141827
DeepSeek 近期动作频频 #21
近日,DeepSeek 在 GitHub 开源了高性能 GPU 算子库
TileKernels。同时,该团队还更新了重构后的
DeepEP v2。此外,社区发现 DeepSeek API 疑似上线了与官网快速模式一致的模型版本。
DeepSeek 近期在产品与技术生态上有多项更新。
在开源项目方面,该公司在 GitHub 上发布了完全重构的专家并行通信库 DeepEP v2。据相关测试数据显示,在延续 DeepSeek V3 模型配置下,其峰值性能达初代 1.3 倍且流处理器占用降低多达 4 倍,并引入了多项零流处理器消耗的实验性特性。
同时,官方还开源了基于 TileLang 构建的高性能 GPU 算子库 TileKernels。该项目以 MIT 协议发布,主要面向大语言模型训练与推理场景。
在产品端,有社区用户发现 DeepSeek 的 API 悄然更新,疑似推出了与官网快速模式一致的模型版本。
相关链接:
提示:内容由AI辅助创作,可能存在幻觉和错误。